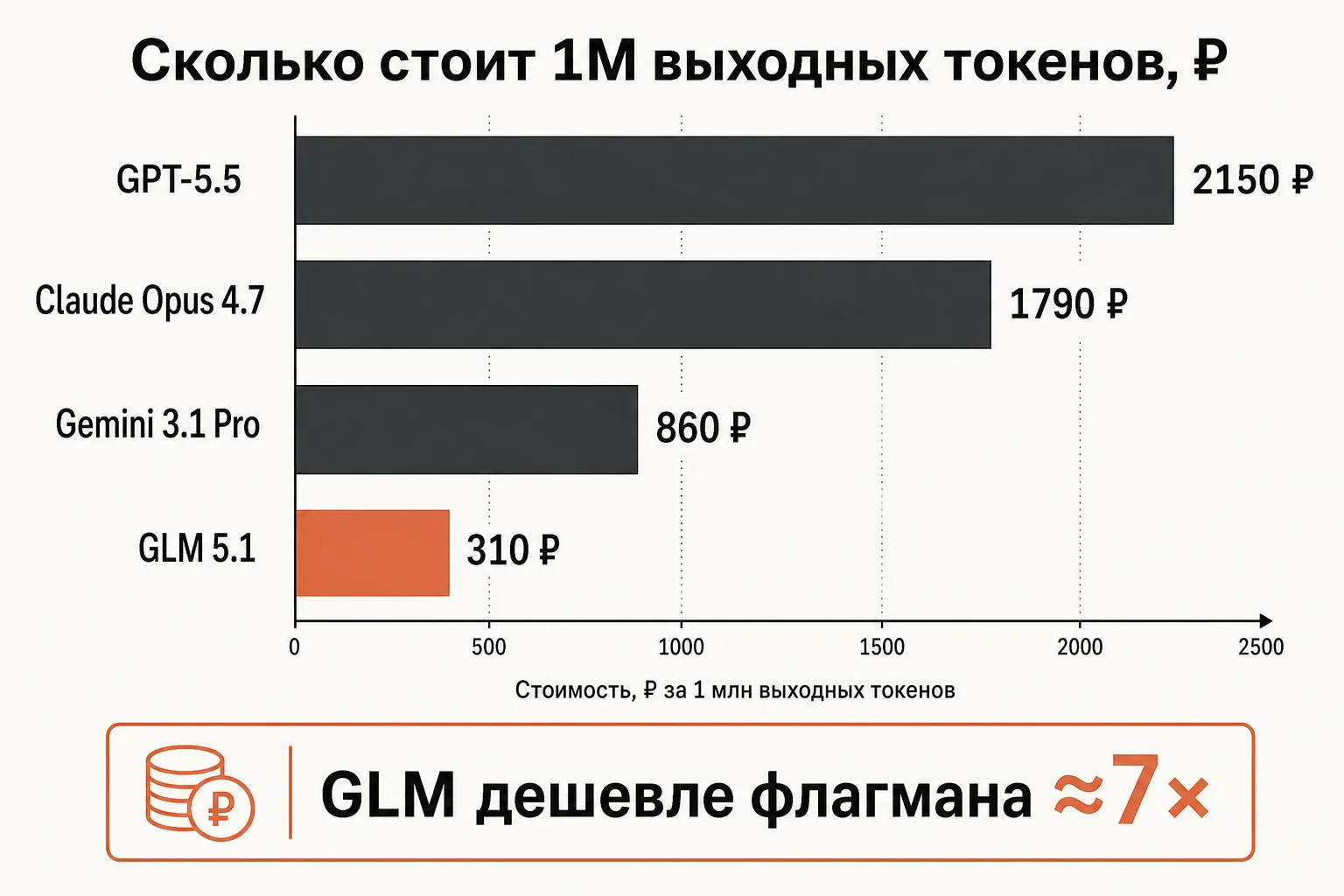
GLM 5.1 — reasoning-модель от китайской компании Z.ai (бывший Zhipu AI). Через Promptra она стоит 100 ₽ за 1M входных токенов и 310 ₽ за 1M выходных — это цена 1-в-1 с официальным прайсом Z.ai ($1.4 и $4.4 за 1M) по курсу ЦБ РФ на 27.05.2026 (71.668 ₽/$), без наценки на токены. Контекстное окно — 202 752 токена, максимум на выход — 65 536 токенов. Это модель с длинной цепочкой рассуждений (reasoning), которая стоит в разы дешевле западных флагманов: её выход дешевле, чем у GPT-5.5, в семь раз, а вход — в три с половиной раза. Подключается она как OpenAI-совместимый endpoint: в коде меняется один параметр base_url, остальное остаётся прежним. Оплата идёт на российское юр.лицо с полным пакетом закрывающих документов через ЭДО.
Главный вопрос про GLM не «насколько она хороша вообще», а «на каких задачах она достаточно хороша, чтобы платить за неё в разы меньше». Reasoning-модель за 310 ₽ против 2150 ₽ — это не «то же самое, но дешевле», у GLM свои сильные и слабые места. Ниже разберём, что это за модель, сколько она стоит на реальных сценариях, где китайская LLM с длинным контекстом выигрывает у флагманов по соотношению цена/задача, чем GLM 5.1 отличается от более дешёвой GLM-4.5, и как подключить её из России без VPN. Все цены — на 2026-05-29.
Что такое GLM 5.1 и для каких задач
GLM (General Language Model) — линейка моделей китайской лаборатории Z.ai. GLM 5.1 — её reasoning-версия: модель не просто отвечает «в лоб», а выстраивает внутреннюю цепочку рассуждений перед финальным ответом. Это тот же класс архитектуры, что у reasoning-режимов западных флагманов, — модель «думает» дольше там, где задача требует многошагового вывода: математика, логика, разбор сложных условий, планирование в агентных сценариях.
Практическая ниша GLM 5.1 — это задачи, где нужен качественный reasoning и/или длинный контекст, но бюджет не позволяет гонять каждый запрос через флагман за 2000+ ₽ за миллион токенов выхода. Модель хорошо подходит, когда у вас большой поток reasoning-запросов (например, аналитика по документам, проверка логических условий, генерация структурированного вывода с обоснованием), и где разница в качестве между GLM и топовой моделью не оправдывает семикратной разницы в цене выхода.
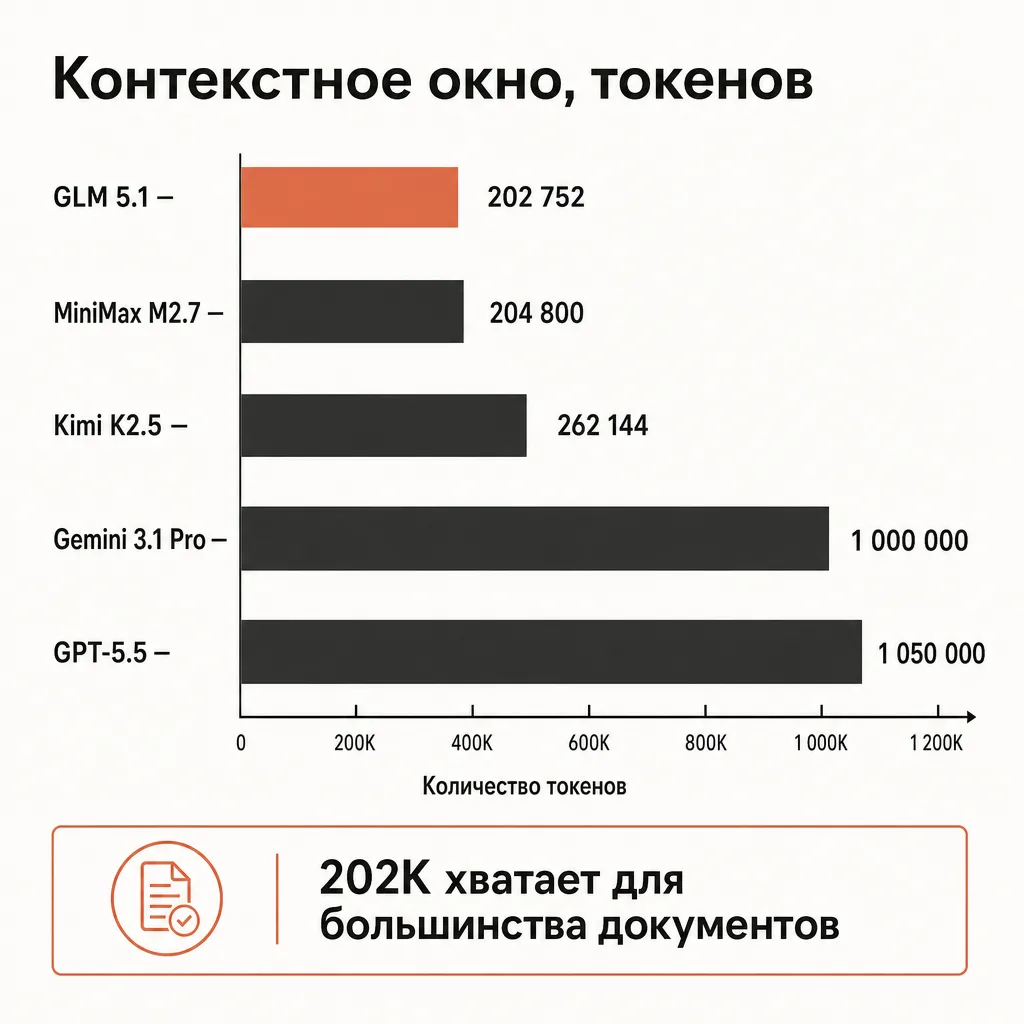
Важно сразу обозначить честные границы. GLM 5.1 — текстовая модель: на вход принимает только текст, изображения и аудио не понимает. Контекст у неё 202 752 токена — это много для большинства задач, но втрое меньше, чем миллион у Gemini 3.1 Pro или DeepSeek V4 Pro. На сложнейших задачах верхнего края (где обычно и сравнивают флагманы) западные топ-модели по качеству, как правило, впереди. GLM 5.1 берут не потому, что она «лучшая», а потому, что на конкретном классе задач она достаточна — при кратно меньшей цене.
Ключевые характеристики из нашего каталога:
| Параметр | Значение |
|---|---|
| Идентификатор модели | z-ai/glm-5.1 |
| Провайдер | Z.ai (Zhipu AI) |
| Тип | reasoning-модель |
| Контекстное окно | 202 752 токена |
| Максимум на выход | 65 536 токенов |
| Модальности входа | текст |
| Модальности выхода | текст |
| Endpoint | chat (OpenAI-совместимый) |
Контекст в 202 752 токена — это ориентировочно 140–150 тысяч слов русского текста или примерно 10 000 строк кода. В одно окно помещается крупный документ, объёмное ТЗ, несколько договоров или кодовая база небольшого сервиса. Выход в 65 536 токенов (около 45–50 тысяч слов) с запасом покрывает длинные структурированные ответы и развёрнутые reasoning-цепочки.

Цена GLM 5.1 в рублях: полная таблица
Promptra не накручивает наценку на токены. Стоимость модели равна официальному прайсу Z.ai, пересчитанному в рубли по курсу ЦБ РФ. Сервисная комиссия 5% берётся только при пополнении баланса, а не с каждого запроса, поэтому в расчётах за токены её нет. Базовый прайс Z.ai публикуется на официальной странице цен Z.ai.
| Тип токенов | Цена Z.ai (USD за 1M) | Цена Promptra (₽ за 1M) |
|---|---|---|
| Вход (input) | $1.40 | 100 ₽ |
| Выход (output) | $4.40 | 310 ₽ |
Курс пересчёта: 1 USD = 71.668 ₽ (ЦБ РФ на 27.05.2026). Арифметика: $1.40 × 71.668 = 100.34 ₽, $4.40 × 71.668 = 315.34 ₽. В каталоге значения округлены до 100 и 310 ₽ — фактический счёт считается по курсу ЦБ на день пополнения, поэтому в разные дни рублёвая цифра слегка плавает вслед за курсом, а долларовая ставка остаётся фиксированной.
Чтобы понимать порядок расходов, прикинем стоимость типовых сценариев. У reasoning-моделей выход часто заметно больше входа за счёт «размышлений», поэтому именно output обычно формирует основной счёт.
| Сценарий | Вход | Выход | Стоимость |
|---|---|---|---|
| Короткий reasoning-запрос | 1K | 2K | ≈ 0.72 ₽ |
| Разбор документа с выводами | 30K | 5K | ≈ 4.55 ₽ |
| Логическая задача с длинным выводом | 5K | 20K | ≈ 6.7 ₽ |
| Анализ кодовой базы | 60K | 8K | ≈ 8.48 ₽ |
Цифры приблизительные и зависят от точного количества токенов в ваших данных. Формула простая: (входные_токены / 1 000 000 × 100) + (выходные_токены / 1 000 000 × 310). Реальный расход всегда видно в дашборде по факту запроса.
Сравните эти суммы с теми же сценариями на флагмане: разбор документа, который у GLM 5.1 стоит ≈4.5 ₽, на GPT-5.5 обошёлся бы примерно в 22.6 ₽ — впятеро дороже. На потоке в сотни тысяч запросов в месяц разница превращается в существенную статью бюджета.
GLM 5.1 против флагманов: где китайская модель выигрывает по цене
Прямое сравнение «GLM лучше или хуже GPT-5.5» бессмысленно — это модели разных весовых категорий по цене. Правильный вопрос — на каких задачах семикратная экономия на выходе оправдана. Сведём GLM 5.1 и три западных флагмана в таблицу (цены — из нашего каталога, 1-в-1 с прайсом провайдеров по курсу ЦБ).
| Модель | Вход (₽/1M) | Выход (₽/1M) | Контекст | Макс. выход | Класс |
|---|---|---|---|---|---|
| GLM 5.1 | 100 ₽ | 310 ₽ | 202 752 | 65 536 | Reasoning, бюджет |
| Gemini 3.1 Pro | 140 ₽ | 860 ₽ | 1M | — | Флагман, мультимодал |
| Claude Opus 4.7 | 350 ₽ | 1790 ₽ | 1M | 128K | Флагман, код/агенты |
| GPT-5.5 | 350 ₽ | 2150 ₽ | 1.05M | 128K | Флагман, reasoning |
USD-прайс для справки: GLM 5.1 — $1.4/$4.4, Gemini 3.1 Pro — $2/$12, Claude Opus 4.7 — $5/$25, GPT-5.5 — $5/$30. Источники — прайс Z.ai, прайс Google, прайс Anthropic, прайс OpenAI.
Разрыв виден сразу. По выходу GLM 5.1 (310 ₽) дешевле Gemini 3.1 Pro в 2.8 раза, дешевле Claude Opus 4.7 в 5.8 раза и дешевле GPT-5.5 почти в 7 раз. По входу — дешевле флагманов OpenAI и Anthropic в 3.5 раза. Это и есть та экономия, ради которой имеет смысл рассматривать китайскую модель.
Где GLM 5.1 — разумный выбор:
- Большой поток reasoning-задач с предсказуемой сложностью. Если у вас тысячи однотипных логических разборов в день (проверка условий, классификация с обоснованием, структурированный вывод), и качества GLM на них хватает — гонять их через флагман за 2150 ₽/1M выхода нерационально.
- Работа с длинными документами в пределах 200K токенов. 202 752 токена покрывают большинство реальных документов и кодовых баз. Если вам не нужен миллионный контекст, переплачивать за него (как у Gemini или GPT-5.5) незачем.
- Бюджетные пайплайны, где output раздувается. Reasoning-модели генерируют много выходных токенов. Чем дороже выход, тем больнее это бьёт по счёту. У GLM выход в разы дешевле — на «болтливых» reasoning-сценариях экономия максимальна.
Где флагманы всё ещё впереди:
- Задачи верхнего края сложности. Самый трудный код с длинными зависимостями, тонкие агентные пайплайны, где цена ошибки высока, — здесь Claude Opus 4.7 и GPT-5.5 по качеству, как правило, надёжнее. Разбор флагманов мы собрали в обзоре топ-5 LLM 2026.
- Мультимодальность. GLM 5.1 не понимает изображения и аудио. Нужен анализ скриншотов, диаграмм, голоса — берите Gemini 3.1 Pro или GPT-5.5.
- Контекст свыше 200K. Очень длинные документы, которые не влезают в 202 752 токена, требуют моделей с миллионным окном.
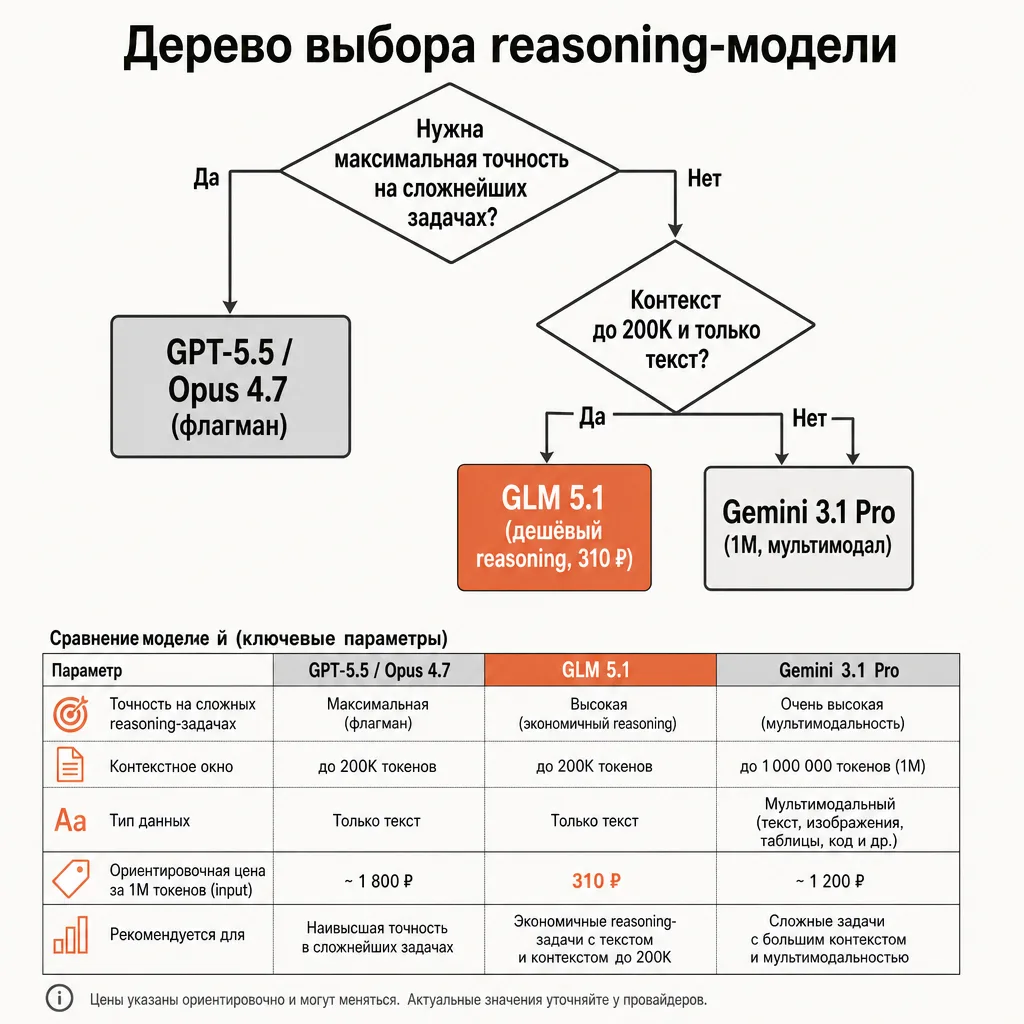
GLM 5.1 vs GLM-4.5: когда платить больше, а когда — нет
Внутри линейки Z.ai есть выбор: помимо GLM 5.1 доступна более старая и более дешёвая GLM-4.5. По данным официального прайса Z.ai, GLM-4.5 стоит $0.60 за 1M входных токенов и $2.20 за 1M выходных — это примерно вдвое дешевле GLM 5.1 по входу и вдвое дешевле по выходу.
Переведём для наглядности в рубли по тому же курсу ЦБ (71.668 ₽/$). Это производные оценки (точные рублёвые цифры GLM-4.5 формируются по курсу на день оплаты, как и для всех моделей):
| Модель | Вход (USD/1M) | Выход (USD/1M) | Вход (₽/1M, оценка) | Выход (₽/1M, оценка) |
|---|---|---|---|---|
| GLM 5.1 | $1.40 | $4.40 | 100 ₽ | 310 ₽ |
| GLM-4.5 | $0.60 | $2.20 | ≈ 43 ₽ | ≈ 158 ₽ |
Возникает резонный вопрос: если GLM-4.5 вдвое дешевле, зачем вообще GLM 5.1? Ответ — в поколении. GLM 5.1 новее и сильнее в reasoning: на задачах, требующих многошагового рассуждения, разница в качестве обычно заметна и оправдывает доплату. GLM-4.5 — более старая модель; на сложном reasoning она чаще «срывается».
Практическая логика выбора между ними та же, что и при выборе между флагманом и универсалом:
- Берите GLM 5.1, когда задача требует именно reasoning — логика, математика, многошаговые выводы, разбор сложных условий. Здесь новое поколение окупается.
- Берите GLM-4.5, когда задачи проще и важнее цена — массовая генерация текста, простые ответы, обработка потока, где глубокий reasoning не нужен. Вдвое дешевле при достаточном качестве.
Это та же стратегия, которую применяют с любыми семействами моделей: дешёвая версия на простом потоке, более сильная — только там, где она реально меняет результат. Промежуточный вариант между бюджетными китайскими моделями — это ещё и Qwen 3.6 Plus от Alibaba с миллионным контекстом и ценой 20/130 ₽; если вам важен очень длинный контекст при минимальной цене, имеет смысл сравнить GLM с Qwen.
Как подключить GLM 5.1 из России: drop-in через OpenAI SDK
Технически GLM 5.1 через Promptra подключается так же, как любая другая модель, — потому что API совместим с OpenAI на уровне протокола. Это удобно: если у вас уже есть код на OpenAI SDK, переход на GLM сводится к смене одного параметра base_url и идентификатора модели. Никаких отдельных китайских SDK, регистрации на платформе Z.ai и оплаты зарубежной картой не требуется.
Python
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx", # ключ Promptra
base_url="https://api.promptra.ru/v1", # единственное изменение
)
response = client.chat.completions.create(
model="z-ai/glm-5.1",
messages=[
{"role": "system", "content": "Ты — аналитик. Рассуждай пошагово."},
{"role": "user", "content": "Сравни два варианта по критериям цены и риска."},
],
)
print(response.choices[0].message.content)Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "prm-xxxxxxxxxxxx",
baseURL: "https://api.promptra.ru/v1", // единственное изменение
});
const response = await client.chat.completions.create({
model: "z-ai/glm-5.1",
messages: [
{ role: "system", content: "Ты — аналитик. Рассуждай пошагово." },
{ role: "user", content: "Сравни два варианта по критериям цены и риска." },
],
});
console.log(response.choices[0].message.content);Хорошая практика: модель и base_url в переменных окружения
Чтобы переключаться между моделями без правок кода (например, гонять простые запросы на дешёвой модели, а reasoning — на GLM), держите endpoint, ключ и идентификатор модели в .env:
import os
from openai import OpenAI
# В .env:
# OPENAI_API_KEY=prm-xxxxxxxxxxxx
# OPENAI_BASE_URL=https://api.promptra.ru/v1
# LLM_MODEL=z-ai/glm-5.1
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_BASE_URL"],
)
response = client.chat.completions.create(
model=os.environ["LLM_MODEL"],
messages=[{"role": "user", "content": "Привет"}],
)Проверить, что подключение работает, можно одним curl-запросом без всякого SDK:
curl https://api.promptra.ru/v1/chat/completions \
-H "Authorization: Bearer prm-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "z-ai/glm-5.1",
"messages": [{"role": "user", "content": "ping"}]
}'Если в ответ пришёл JSON с полем choices — модель отвечает, можно подключать в продакшен. Поскольку GLM, GPT, Claude и Gemini доступны через один и тот же endpoint, в коде можно держать роутинг: дешёвую модель на массовый поток, флагман — на сложные запросы, GLM — на reasoning среднего уровня. Меняется только строка model.

Контекст 202 752 и максимум выхода 65 536: что это значит на практике
Помимо цены, у GLM 5.1 есть архитектурные лимиты, которые важно учитывать при проектировании:
- Контекстное окно — 202 752 токена. Это суммарный объём «вход плюс всё, что модель удерживает в рамках запроса». Около 140–150 тысяч слов русского текста. Для подавляющего большинства задач этого достаточно: крупный документ, объёмное ТЗ, кодовая база небольшого сервиса помещаются целиком. Если же ваши данные стабильно превышают 200K токенов (длинные юридические массивы, большие логи), смотрите в сторону моделей с миллионным окном — Gemini 3.1 Pro или DeepSeek V4 Pro.
- Максимум на выход — 65 536 токенов. Сколько модель может сгенерировать в одном ответе — примерно 45–50 тысяч слов. Для reasoning-цепочек и развёрнутых структурированных ответов этого с запасом. Если нужен документ длиннее лимита выхода, генерацию разбивают на части с продолжением контекста.
- Только текстовый вход. GLM 5.1 не принимает изображения и аудио. Это ограничение, а не недостаток цены: если задача чисто текстовая (а большинство reasoning-задач именно такие), мультимодальность вам и не нужна, и платить за неё (как в мультимодальных флагманах) незачем.
- Endpoint
chat. Модель работает через стандартный chat-completions API, совместимый с OpenAI SDK, — ровно как в примерах выше.
Отдельно про контекст: 202K — это «золотая середина» рынка. Меньше, чем у миллионных моделей, но достаточно для реальных документов, и при этом без переплаты за контекст, который вы не используете. Если 95% ваших задач укладываются в 200K, миллионное окно — это деньги на ветер.
Сколько стоит GLM 5.1 в месяц: прикидка для команды
Чтобы цена в ₽ за миллион токенов превратилась в понятную цифру месячного бюджета, прикинем три профиля нагрузки. Допущения указаны рядом — подставьте свои.
| Профиль | Запросов/мес | Средний вход | Средний выход | Токенов вход/мес | Токенов выход/мес | Стоимость/мес |
|---|---|---|---|---|---|---|
| Небольшой reasoning-поток | 50 000 | 2K | 3K | 100M | 150M | ≈ 56 500 ₽ |
| Средняя нагрузка | 300 000 | 3K | 4K | 900M | 1.2B | ≈ 462 000 ₽ |
| Аналитика по документам | 30 000 | 40K | 6K | 1.2B | 180M | ≈ 175 800 ₽ |
Расчёт прямой: входные токены за месяц делим на миллион и умножаем на 100 ₽, выходные — на 310 ₽, складываем. Например, для «небольшого reasoning-потока»: 100 × 100 + 150 × 310 = 10 000 + 46 500 = 56 500 ₽.
Для сравнения: тот же «небольшой reasoning-поток» на GPT-5.5 (350/2150 ₽) стоил бы 100 × 350 + 150 × 2150 = 35 000 + 322 500 = 357 500 ₽ в месяц — против 56 500 ₽ на GLM. Разница более чем в шесть раз, и формирует её именно выход: у reasoning-нагрузки много выходных токенов, а выход GLM в семь раз дешевле. Это и есть ключевой аргумент в пользу китайской модели на подходящих задачах. Сервисная комиссия Promptra (5%) при этом берётся один раз при пополнении баланса, а не с каждого запроса.
Разумная архитектура для команды — гибридная: GLM 5.1 (или ещё более дешёвая GLM-4.5) на массовом reasoning-потоке, флагман — только на запросах верхнего края сложности, где он реально меняет результат. Поскольку все модели доступны через один endpoint, такой роутинг — это вопрос одной строки model в коде.
Оплата и документы для юр.лица
Для команд в компаниях важна не только цена токена, но и то, как эти расходы проходят по бухгалтерии. Promptra принимает оплату на российское юр.лицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — с полным пакетом закрывающих документов: договор-оферта, счёт, акт, счёт-фактура, УПД. Документооборот идёт через ЭДО (Диадок, СБИС), что удобно для корпоративной бухгалтерии — документы автоматически проводятся в учётной системе.
Для китайских моделей это особенно актуально. Платформа Z.ai — зарубежный сервис, оплата напрямую требует иностранной карты или счёта, а закрывающих документов российского формата вы не получите. Расход на API без правильно оформленной первички бизнесу сложно корректно учесть. Через Promptra GLM 5.1 оплачивается в рублях с полным комплектом документов — расход целиком ложится в учёт компании как обычная услуга. Юридическую и бухгалтерскую сторону работы с зарубежными LLM на юр.лицо мы подробно разобрали в гайде легально ли использовать AI API на юрлицо в РФ.
FAQ
Сколько стоит GLM 5.1 в рублях?
Через Promptra — 100 ₽ за 1M входных токенов и 310 ₽ за 1M выходных. Это прямой пересчёт официального прайса Z.ai ($1.4 и $4.4 за 1M) по курсу ЦБ РФ (71.668 ₽/$ на 27.05.2026), без наценки на токены. Фактический счёт считается по курсу ЦБ на день пополнения баланса. Сервисная комиссия 5% берётся отдельно — только при пополнении, а не с каждого запроса.
Чем GLM 5.1 отличается от GLM-4.5?
GLM 5.1 — более новое поколение и сильнее в reasoning; GLM-4.5 — более старая и примерно вдвое дешевле ($0.60/$2.20 против $1.40/$4.40). Берите GLM 5.1 на задачах с многошаговым рассуждением (логика, математика, разбор сложных условий), где новое поколение окупается. Берите GLM-4.5 на простых массовых задачах, где глубокий reasoning не нужен, а важнее цена.
Когда GLM 5.1 выгоднее GPT-5.5 или Claude?
Когда задача не требует максимального качества флагмана, а нужен крепкий reasoning при кратно меньшей цене. Выход GLM (310 ₽/1M) дешевле GPT-5.5 почти в 7 раз и Claude Opus 4.7 в 5.8 раза. На большом потоке reasoning-задач средней сложности и при работе с документами до 200K токенов экономия существенная. На задачах верхнего края сложности и там, где нужна мультимодальность, флагманы по-прежнему предпочтительнее.
Какой контекст у GLM 5.1?
Контекстное окно — 202 752 токена (примерно 140–150 тысяч слов русского текста), максимум на выход — 65 536 токенов. Этого достаточно для большинства документов и кодовых баз. Если ваши данные стабильно превышают 200K токенов, смотрите модели с миллионным окном — Gemini 3.1 Pro или DeepSeek V4 Pro.
Как подключить GLM 5.1 из России без VPN?
Через OpenAI-совместимый endpoint Promptra. В коде на OpenAI SDK меняется один параметр — base_url на https://api.promptra.ru/v1, модель указывается как z-ai/glm-5.1, ключ Z.ai не нужен — используется ключ Promptra. Прямой доступ к платформе Z.ai через VPN и зарубежные карты не требуется: запросы проксируются легально, а оплата идёт в рублях на юр.лицо с закрывающими документами.
Понимает ли GLM 5.1 изображения?
Нет. GLM 5.1 — текстовая модель: на вход принимает только текст, изображения и аудио не обрабатывает. Если нужен анализ скриншотов, диаграмм, фотографий документов или голоса, берите мультимодальные модели — Gemini 3.1 Pro или GPT-5.5.
Если вы хотите посчитать стоимость GLM 5.1 под вашу реальную нагрузку или обсудить, какие задачи перенести на дешёвую reasoning-модель, а какие оставить на флагмане, — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Поможем прикинуть бюджет под ваш профиль запросов и собрать гибридный роутинг — GLM там, где его достаточно, и флагман там, где он реально нужен.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.