
Лучшая нейросеть 2026 — это не одна модель, а правильное соответствие модели и задачи. Если коротко: для сложного кода и долгого reasoning берите Claude Opus 4.7 (350/1790 ₽ за 1М токенов) или GPT-5.5 (350/2150 ₽); для большинства production-задач хватит Claude Sonnet 4.6 (210/1070 ₽) или GPT-5.4 (170/1070 ₽); для длинного контекста и мультимодала с аудио — Gemini 3.1 Pro (140/860 ₽); а для дешёвой массовой генерации и chat — DeepSeek V4 Pro (30/60 ₽). Все цены — рублёвые ценники из каталога Promptra, 1-в-1 с провайдером по курсу ЦБ на 27.05.2026 (71.668 ₽/$), без наценки на токены.
Вопрос «какая нейросеть лучшая вообще» в 2026 потерял смысл. Между флагманом за 2150 ₽ и сверхдешёвой моделью за 60 ₽ — разница в стоимости миллиона output-токенов в тридцать с лишним раз. Платить премиум там, где справится модель в 30 раз дешевле, — технический долг, который тихо копится и больно вылезает в счёте. Экономить же на reasoning там, где цена ошибки высокая, — ещё дороже. Правильный вопрос: какую нейросеть выбрать под конкретную задачу.
Эта статья — практический гид. Разбираем шесть типовых задач — код, текст и контент, reasoning, длинный контекст, мультимодал, бюджет — и по каждой даём конкретную рекомендацию с ценой в рублях, а в конце сводим всё в дерево выбора. Все рублёвые цифры — вербатим из каталога моделей (ровно то, что видно на странице тарифов); оценки качества — со ссылками на первоисточники или помечены как качественные. Если нужно сравнение лоб в лоб по бенчмаркам — это в обзоре топ-5 LLM 2026 года; здесь фокус не на «кто сильнее», а на «что брать подо что».
Почему «одной лучшей нейросети» не существует
Три структурных факта рынка в 2026 объясняют, почему выбор «по умолчанию» проигрывает выбору «под задачу».
Первое — расщепление по цене. Линейка моделей разъехалась на лиги, между которыми разрыв по стоимости в десятки раз. Сверху — флагманы premium-reasoning (Opus 4.7, GPT-5.5) по 1790–2150 ₽ за миллион output-токенов. В середине — value-tier (Sonnet 4.6, GPT-5.4, Gemini 3.1 Pro) по 860–1070 ₽. Снизу — сверхдешёвый слой (DeepSeek V4 Pro, Qwen 3.6 Plus, MiniMax M2.7) по 60–130 ₽. Когда разница 30-кратная, выбор модели становится экономическим решением, а не только техническим.
Второе — расщепление по сильным сторонам. Нет модели, которая выигрывает каждый бенчмарк. По независимым агрегаторам разные модели лидируют в разных дисциплинах: одни — в агентском кодировании, другие — в reasoning и общих знаниях, третьи — в работе с документами. Универсального чемпиона нет — есть профили специализации. Поэтому зрелые команды строят не «выбор одной модели навсегда», а mixture-of-models routing — разные подзадачи уходят к разным моделям.
Третье — длинный контекст стал коммодити. Окно 1М токенов есть уже у Opus 4.7, Sonnet 4.6, GPT-5.5, GPT-5.4, Gemini 3.1 Pro и DeepSeek V4 Pro. Но «модель принимает 1М токенов» не равно «модель одинаково хорошо использует всю эту длину»: размер окна — потолок, а не гарантия качества retrieval.
Вывод простой: правильная архитектура — абстракция над LLM, позволяющая менять модель под задачу без передеплоя кода. Для этого и нужен агрегатор: один API-ключ, OpenAI-совместимый endpoint, все модели сразу. Дальше — разбор по задачам.
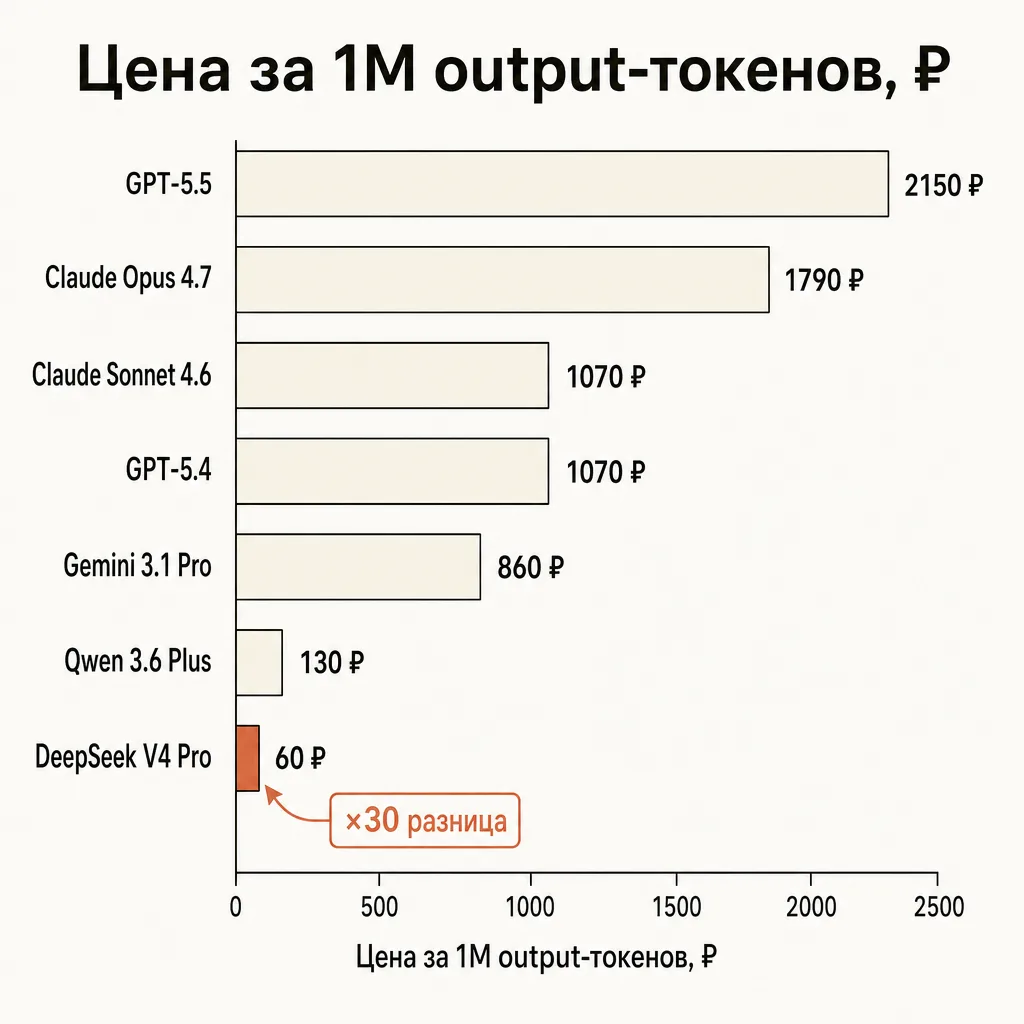
Задача 1: код и разработка
Код — самая требовательная к качеству задача и одновременно самая чувствительная к нему по деньгам: одна правильная итерация флагмана экономит десяток итераций слабой модели. Здесь работает чёткая трёхступенчатая лестница.
Дефолт для команды — Claude Sonnet 4.6 (210/1070 ₽). Для подавляющего большинства задач — написать функцию, поправить баг, отрефакторить модуль, объяснить чужой код — Sonnet 4.6 даёт качество, близкое к флагманскому, при цене втрое ниже Opus и впятеро ниже output GPT-5.5. Контекст — 1М токенов, чего хватает на крупные файлы и diff целиком. Это та модель, которую большинство production-команд в 2026 поставили дефолтом для code-ассистентов. Подробный разбор подключения Claude по API — на странице Claude API за рубли.
Сложные задачи и большие codebase — Claude Opus 4.7 (350/1790 ₽). Когда нужно держать в голове репозиторий на сотни тысяч строк, вести многошаговую агентскую сессию или решать архитектурно нетривиальную задачу, Opus 4.7 стабильнее: меньше «теряет нить» на длинной сессии, аккуратнее с контекстом. Это флагман Anthropic, позиционируемый именно под сложный код, агентов и долгий reasoning. Важный нюанс по деньгам: Opus 4.7 использует новый токенайзер, который на одном и том же тексте может расходовать до +35% токенов — это надо закладывать в бюджет, иначе фактический счёт окажется выше расчётного.
Топ агентского кодирования — GPT-5.5 (350/2150 ₽). Флагман OpenAI, релиз 24.04.2026, контекст 1.05М токенов и нативная мультимодальность. Для агентских coding-задач уровня «закрыть сложный GitHub-issue в legacy-проекте с первой попытки» — сильнейший выбор. Цена самая высокая в линейке по output (2150 ₽), плюс при входе свыше 272K токенов действует повышенный тариф (×2 на вход, ×1.5 на выход — производная ставка от каталожной USD-цены). Как подключить GPT по API — на странице ChatGPT API за рубли.
Дёшево и в код — DeepSeek V4 Pro (30/60 ₽). Open-weight модель, сильная в коде и матлогике, контекст 1М токенов. На рутинных задачах — сгенерировать boilerplate, написать тесты, объяснить snippet — её качества часто достаточно, а цена в десятки раз ниже флагманов. Важно про цену: в каталоге действует промо −75% до 31.05.2026 (30/60 ₽); базовый тариф после окончания промо — около 120/240 ₽ (производная от USD ≈ $1.74/$3.48). Для непрерывного code-ассистента это всё равно радикально дешевле премиума.
| Задача в коде | Рекомендация | Цена ₽ (вход/выход за 1М) |
|---|---|---|
| Дефолт команды, ежедневные правки | Claude Sonnet 4.6 | 210 / 1070 |
| Сложный код, большие codebase, агенты | Claude Opus 4.7 | 350 / 1790 |
| Топ агентского кодирования | GPT-5.5 | 350 / 2150 |
| Дёшево, рутина и boilerplate | DeepSeek V4 Pro | 30 / 60 (промо до 31.05) |
| Специализация на code-review | GPT-5.3 Codex | 120 / 1000 |
Практический паттерн команд в 2026: Sonnet 4.6 как primary, Opus 4.7 или GPT-5.5 — как явный эскалейт на сложных задачах. Через OpenAI-совместимый API это переключение — одна строчка с заменой имени модели, без переписывания кода.
Задача 2: текст и контент
Генерация текста — статьи, продуктовые описания, письма, посты, рерайт — это задача, где платишь в основном за output-токены, а планку качества часто закрывает редактор-человек на финальной правке. Поэтому здесь экономика смещает выбор вниз по цене сильнее, чем в коде.
Массовый контент — DeepSeek V4 Pro (30/60 ₽) или Qwen 3.6 Plus (20/130 ₽). Для потоковой генерации (карточки товаров, SEO-черновики, шаблонные письма) качества сверхдешёвых моделей обычно достаточно, особенно с человеком на вычитке. Разница в счёте — двукратный порядок против флагманов. Qwen 3.6 Plus к тому же многоязычная open-weight модель Alibaba с контекстом 1М токенов и сильна в нескольких языках.
Качественный контент с характером — Claude Sonnet 4.6 (210/1070 ₽). Когда важен тон, связность и «человечность» длинного текста без тяжёлой редактуры, модели Anthropic традиционно дают аккуратный, естественный русский. Sonnet 4.6 — разумный баланс: заметно лучше дешёвого слоя по стилю, заметно дешевле флагманов.
Премиум-копирайтинг и редкие сложные тексты — Claude Opus 4.7 (350/1790 ₽). Если текст идёт «как есть» в продакшн без правок (лендинг, важная рассылка, юридически чувствительный документ), флагман окупает наценку: меньше фактических ошибок, аккуратнее структура. Но это нишевый сценарий — на 80% контент-задач он избыточен.
| Сценарий контента | Рекомендация | Цена ₽ (вход/выход за 1М) |
|---|---|---|
| Массовая генерация, есть редактор | DeepSeek V4 Pro / Qwen 3.6 Plus | 30/60 · 20/130 |
| Качественный текст, минимум правок | Claude Sonnet 4.6 | 210 / 1070 |
| Премиум «в продакшн без правок» | Claude Opus 4.7 | 350 / 1790 |
| Дешёвый универсал OpenAI | GPT-5.4 mini | 50 / 320 |
На объёме в десятки тысяч текстов в месяц разрыв между DeepSeek V4 Pro и флагманом — это та сумма, которую можно перенаправить из счёта за токены в бюджет на людей или продукт.
Задача 3: reasoning, математика и наука
Сложные рассуждения — многоступенчатый анализ, математика, научные вопросы, finance/legal/medical — это та задача, где цена ошибки максимальна и экономить на модели опаснее всего. Здесь выбор сужается до флагманов.
Стабильность в долгих цепочках — Claude Opus 4.7 (350/1790 ₽). Opus традиционно силён там, где надо «думать долго» и держать длинную цепочку рассуждений без срывов. Это наш дефолт-совет для finance, legal и medical — областей, где одна логическая ошибка стоит дороже любой экономии на токенах. По независимым агрегаторам бенчмарков Opus стабильно держится в топ-3 во всех reasoning-дисциплинах — без провалов; детальные таблицы — в обзоре топ-5 LLM.
Лидер в общих знаниях и научном reasoning — Gemini 3.1 Pro (140/860 ₽). Gemini 3.1 Pro Preview — флагман Google с сильным reasoning и широтой знаний по дисциплинам, при этом самый дешёвый среди флагманов по обеим ставкам. Для research, data analysis и научных задач, где важна широта эрудиции, это рациональный выбор — и по качеству, и по цене. Как подключить Gemini по API — на странице Gemini API в России.
Reasoning-флагман OpenAI — GPT-5.5 (350/2150 ₽). GPT-5.5 силён в reasoning и нативно мультимодален; берите его, если экосистема уже завязана на OpenAI или нужна одна модель и под reasoning, и под код, и под мультимодал.
Дёшево и в матлогику — DeepSeek V4 Pro (30/60 ₽). Для задач, где нужно «прикинуть» или прогнать массу однотипных логических проверок без премиум-цены, DeepSeek силён в математике и логике при копеечной стоимости. Для критичных решений — не замена флагману, но отличный первый фильтр.
Главное правило для reasoning: бенчмарк отсекает явно неподходящие модели, но финальное решение — A/B-тест на ваших кейсах. Прогнать сотню своих вопросов через две-три модели стоит копейки и даёт честный personal benchmark вместо чужих таблиц.
Задача 4: длинный контекст
Длинный контекст нужен для RAG с большим корпусом, анализа объёмных документов, кодовых баз целиком, длинных диалогов. К 2026 окно 1М токенов стало почти повсеместным, поэтому выбор идёт не по «у кого больше», а по качеству работы на длине и по экономике.
Лучший баланс качества на длине — Claude Sonnet 4.6 (210/1070 ₽). Контекст 1М, и качество retrieval на длинном окне у Anthropic традиционно стабильно. Для RAG и анализа больших документов это разумный дефолт.
Самый дешёвый длинный контекст среди флагманов — Gemini 3.1 Pro (140/860 ₽). Если ваш типичный запрос укладывается в умеренный объём, а 1М нужен «про запас» на редкие большие запросы, Gemini — самый выгодный по входной ставке. Учтите: у Gemini тарификация зависит от длины контекста, поэтому на стабильно огромных запросах считайте под свой реальный размер — выгода может таять.
Сверхдешёвый длинный контекст — DeepSeek V4 Pro (30/60 ₽). Окно 1М токенов при копеечной цене. Для массового RAG, где важнее объём и цена, чем последняя доля качества retrieval, — сильный кандидат. Качество на длине стоит проверить на своих данных.
Длинные документы среднего объёма — Kimi K2.5 (40/170 ₽). Контекст 262K, хороша для длинных документов, дешевле флагманов. Удобный middle-ground, когда 1М не нужен, а 200K мало.
| Профиль длинного контекста | Рекомендация | Цена ₽ · контекст |
|---|---|---|
| Баланс качества на длине | Claude Sonnet 4.6 | 210/1070 · 1М |
| Дешевле всех среди флагманов | Gemini 3.1 Pro | 140/860 · 1М |
| Сверхдёшево, массовый RAG | DeepSeek V4 Pro | 30/60 · 1М |
| Документы среднего объёма | Kimi K2.5 | 40/170 · 262K |
Ключевой приём экономии в long-context: prompt caching. Если корпус документов стабилен и переиспользуется между запросами, кэширование снижает реальную стоимость в разы (у Anthropic дисконт на cache-hits достигает 90%). В RAG-сценарии это часто главный экономический фактор — важнее выбора самой модели.
Задача 5: мультимодал — изображения, аудио, видео
Мультимодальные задачи делятся на два класса: модель, которая понимает изображение/аудио на входе (vision-LLM), и модель, которая генерирует картинку или видео.
Понимание изображений и документов на входе. Нужна текстовая модель с image- или audio-входом. Gemini 3.1 Pro (140/860 ₽) принимает аудио, image и текст — полноценный мультимодал с самой низкой ценой среди флагманов. GPT-5.5 (350/2150 ₽) силён в общем vision (фото, скриншоты, диаграммы). Claude Opus 4.7 и Sonnet 4.6 тоже принимают изображения и хорошо разбирают скриншоты и документы.
Генерация изображений. В каталоге — Nano Banana Pro и GPT Image 2 (именно GPT Image 2 рисует иллюстрации к этому блогу). Тарификация токенная, зависит от размера и качества кадра — единой ставки «за картинку» нет, стоимость считается под запрос. Разбор — в материале генерация изображений по API.
Генерация видео (тариф за секунду). Топ-качество — Veo 3.1 от Google (28.67 ₽/с в 720–1080p, 43 ₽/с в 4K, с аудио). Дешевле — Seedance 2.0 от ByteDance (3.58–24.37 ₽/с) и Kling v3 (4.52–6.02 ₽/с). Выбор — по требованиям к качеству и бюджету на секунду; разбор — в статье видео по API из России.
| Мультимодальная задача | Рекомендация | Цена |
|---|---|---|
| Понимание изображений + аудио на входе | Gemini 3.1 Pro | 140/860 ₽ за 1М |
| Общий vision (фото, скриншоты) | GPT-5.5 / Claude Sonnet 4.6 | 350/2150 · 210/1070 ₽ |
| Генерация изображений | Nano Banana Pro / GPT Image 2 | токенно, по запросу |
| Премиум-видео с аудио | Veo 3.1 | 28.67–43 ₽/с |
| Бюджетное видео | Seedance 2.0 / Kling v3 | от 3.58 ₽/с · 4.52 ₽/с |
Задача 6: бюджет — максимум качества за минимум денег
Отдельная задача — не «какая лучшая», а «какая лучшая в пределах бюджета». Когда объём запросов большой, а планка качества умеренная (chat-боты, классификация, суммаризация, рерайт, массовые автоматизации), сверхдешёвый слой на типовых запросах даёт качество, неотличимое от среднего tier, при цене в десятки раз ниже.
Абсолютный минимум цены — DeepSeek V4 Pro (30/60 ₽), MiniMax M2.7 (20/80 ₽), Qwen 3.6 Plus (20/130 ₽). Рабочие лошадки массового потока: на простом Q&A, классификации и суммаризации их качество на большинстве запросов сопоставимо со средним tier.
Дешёвый, но «брендовый» — Gemini 3.1 Flash Lite (10/100 ₽) и GPT-5.4 mini (50/320 ₽). Когда хочется минимальной цены, но в рамках экосистемы OpenAI или Google — например, чтобы не плодить провайдеров.
Дешёвый Claude для роутинга — Claude Haiku 4.5 (70/350 ₽). Самая быстрая и дешёвая модель Anthropic, идеальна для роутинга запросов и классификации: дёшево решает «куда отправить этот запрос дальше».
| Бюджетная задача | Рекомендация | Цена ₽ (вход/выход за 1М) |
|---|---|---|
| Минимум цены, массовый поток | DeepSeek V4 Pro / MiniMax M2.7 | 30/60 · 20/80 |
| Многоязычный дешёвый | Qwen 3.6 Plus | 20 / 130 |
| Дешёвый в экосистеме Google | Gemini 3.1 Flash Lite | 10 / 100 |
| Роутинг и классификация на Claude | Claude Haiku 4.5 | 70 / 350 |
Пример масштаба экономии: на профиле «1000 токенов входа + 500 выхода» при миллионе запросов в месяц разница между сверхдешёвой моделью и средним tier измеряется сотнями тысяч рублей в месяц. Если для FAQ-чатбота качества дешёвой модели достаточно (а обычно достаточно), эта сумма — чистая экономия.
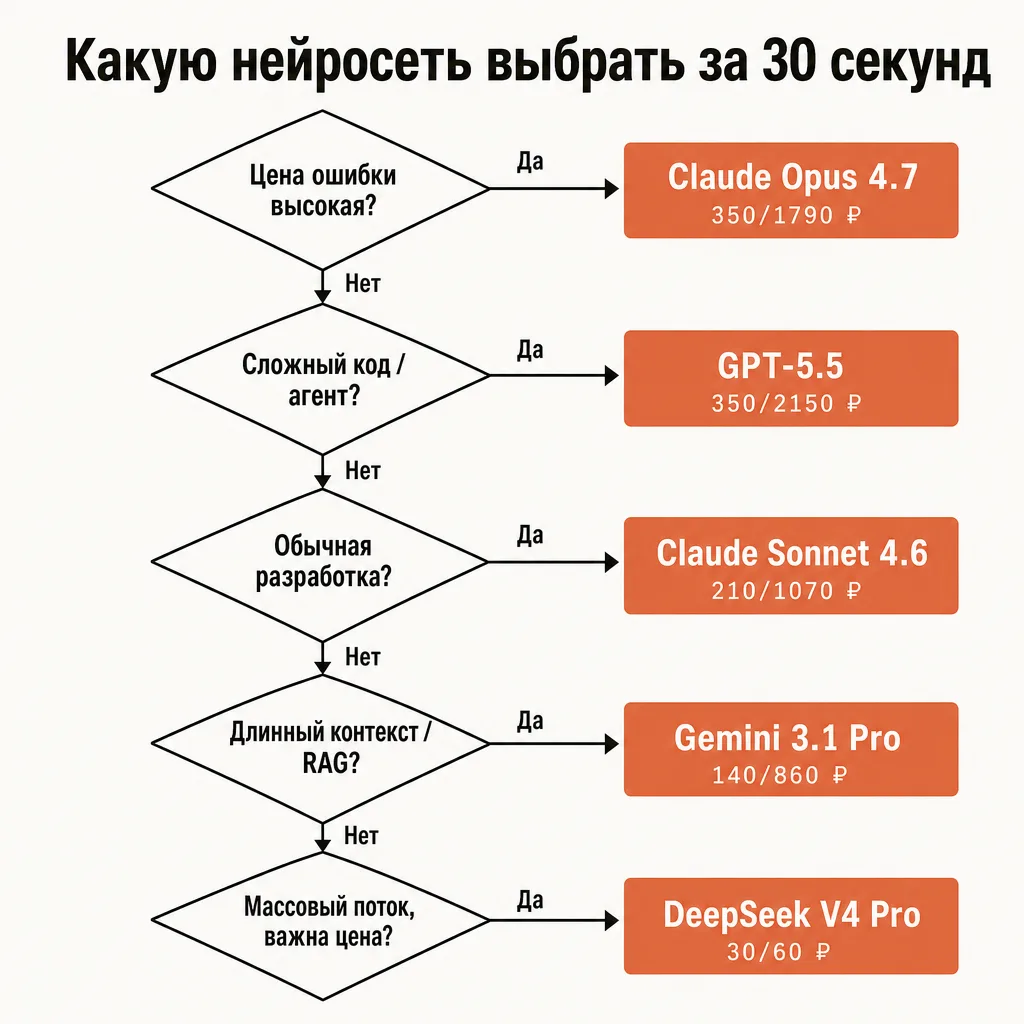
Дерево выбора: какую нейросеть выбрать за 30 секунд
Сведём всё в простой алгоритм. Идите сверху вниз, первое совпадение — ваш выбор.
- Цена ошибки высокая (finance, legal, medical, критичный код)? → Claude Opus 4.7 (350/1790 ₽). Альтернатива под reasoning с широтой знаний — Gemini 3.1 Pro (140/860 ₽).
- Сложный код или агентская сессия в большом проекте? → GPT-5.5 (350/2150 ₽) или Claude Opus 4.7 (350/1790 ₽).
- Обычная разработка, ежедневные задачи? → Claude Sonnet 4.6 (210/1070 ₽) как дефолт, GPT-5.4 (170/1070 ₽) как дешёвый универсал.
- Нужен мультимодал с аудио / понимание изображений? → Gemini 3.1 Pro (140/860 ₽); общий vision — GPT-5.5.
- Генерация картинок или видео? → изображения: Nano Banana Pro / GPT Image 2; видео: Veo 3.1 (премиум) или Seedance 2.0 / Kling v3 (бюджет).
- Длинный контекст / большой RAG? → Claude Sonnet 4.6 (качество) или Gemini 3.1 Pro (цена); сверхдёшево — DeepSeek V4 Pro. Не забудьте prompt caching.
- Массовый поток, умеренное качество, важна цена? → DeepSeek V4 Pro (30/60 ₽), MiniMax M2.7 (20/80 ₽) или Qwen 3.6 Plus (20/130 ₽).
Главный мета-вывод: на реальном продукте обычно работает не одна, а связка из 2–3 моделей — дешёвая на массовый поток, средняя на основную нагрузку, флагман на эскалейт сложных случаев. Это и есть mixture-of-models. Через один OpenAI-совместимый API переключение между ними — смена имени модели в запросе, без нового кода и договора.
Доступность в России: почему это часть выбора модели
Выбор «лучшей нейросети» в России 2026 упирается не только в качество, но и в доступ. Прямая интеграция с OpenAI, Anthropic и Google из РФ затруднена: карты российских банков на оплату не проходят, а обходные пути ненадёжны. DeepSeek и Qwen формально доступнее, но их кабинеты и документация ориентированы на китайскую аудиторию, а доступ нестабилен. В итоге «лучшая модель», к которой нельзя стабильно и легально подключиться с оплатой по-белому, на практике не лучшая.
Российский LLM-агрегатор закрывает этот разрыв:
- Один API-ключ на все модели и OpenAI-совместимый endpoint — drop-in замена в существующем коде. Меняете
base_urlнаhttps://api.promptra.ru/v1и имя модели в форматепровайдер/модель(например,anthropic/claude-opus-4.7). - Оплата на юр.лицо ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) в рублях с полным пакетом закрывающих документов — договор-оферта, счёт, акт, счёт-фактура, УПД через ЭДО (Диадок, СБИС, 1С-ЭДО). Это закрывает требования бухгалтерии и налогового учёта; разбор схемы — в материале легально ли использовать OpenAI и Claude на юрлицо в РФ.
- Цена 1-в-1 с провайдером по курсу ЦБ, без наценки на токены. Сервисная комиссия 5% — только при пополнении баланса, не от токенов.
- Без vendor lock-in: новые модели появляются в каталоге без переписывания кода и нового договора — а значит, mixture-of-models из этой статьи можно собрать в один день.
Минимальный пример на Python (OpenAI SDK):
from openai import OpenAI
client = OpenAI(
base_url="https://api.promptra.ru/v1",
api_key="PROMPTRA_API_KEY",
)
resp = client.chat.completions.create(
model="anthropic/claude-sonnet-4.6", # дефолт под код
messages=[{"role": "user", "content": "Объясни этот diff и предложи фикс"}],
)
print(resp.choices[0].message.content)Чтобы переключить задачу на флагман или на дешёвую модель, меняется только строка model — например, openai/gpt-5.5 под сложный агентский кейс или deepseek/deepseek-v4-pro под массовую генерацию. Остальной код остаётся прежним.
FAQ
Какая нейросеть лучшая в 2026 году?
Единой «лучшей» нет — лучшая зависит от задачи. Под сложный код и долгий reasoning — Claude Opus 4.7 (350/1790 ₽) и GPT-5.5 (350/2150 ₽); под ежедневную разработку — Claude Sonnet 4.6 (210/1070 ₽); под длинный контекст и мультимодал с аудио — Gemini 3.1 Pro (140/860 ₽); под дешёвую массовую генерацию — DeepSeek V4 Pro (30/60 ₽). Цены — рублёвые из каталога Promptra по курсу ЦБ на 27.05.2026.
Какую нейросеть выбрать для кода?
Дефолт для команды — Claude Sonnet 4.6 (210/1070 ₽): качество, близкое к флагманскому, втрое дешевле Opus. Сложные задачи и большие codebase — Claude Opus 4.7 (350/1790 ₽, учитывайте новый токенайзер до +35% токенов). Топ агентского кодирования — GPT-5.5 (350/2150 ₽). Рутина и boilerplate дёшево — DeepSeek V4 Pro (30/60 ₽).
Какая нейросеть лучшая для генерации текста и контента?
Для массового контента с редактором на вычитке — DeepSeek V4 Pro (30/60 ₽) или Qwen 3.6 Plus (20/130 ₽), экономия двукратного порядка против флагманов. Для качественного текста с минимумом правок — Claude Sonnet 4.6 (210/1070 ₽). Для премиум-материалов «в продакшн без правок» — Claude Opus 4.7 (350/1790 ₽), но это нишевый сценарий.
Какую нейросеть выбрать для длинного контекста и RAG?
Окно 1М токенов есть у Sonnet 4.6, Gemini 3.1 Pro и DeepSeek V4 Pro. Лучший баланс качества на длине — Claude Sonnet 4.6 (210/1070 ₽); самый дешёвый среди флагманов — Gemini 3.1 Pro (140/860 ₽); сверхдёшево — DeepSeek V4 Pro (30/60 ₽). Ключ к экономии в RAG — prompt caching: при стабильном корпусе он снижает стоимость в разы.
Какая нейросеть самая дешёвая и при этом нормальная по качеству?
DeepSeek V4 Pro (30/60 ₽), MiniMax M2.7 (20/80 ₽) и Qwen 3.6 Plus (20/130 ₽). На типовых задачах (chat, классификация, суммаризация, рерайт) их качество сопоставимо со средним tier, а цена в десятки раз ниже. У DeepSeek V4 Pro до 31.05.2026 действует промо −75% (после — около 120/240 ₽).
Как подключить эти нейросети из России?
Через российский агрегатор с OpenAI-совместимым API: меняете base_url на https://api.promptra.ru/v1 и имя модели в формате провайдер/модель. Оплата в рублях на юр.лицо с полным пакетом закрывающих документов через ЭДО, цена на токены 1-в-1 с провайдером по курсу ЦБ. Все модели доступны по одному ключу — можно собрать mixture-of-models под разные задачи.
Выбор модели под задачу — половина дела; вторая половина — стабильный и легальный доступ к ней из России. Если хотите подобрать связку моделей под ваш профиль нагрузки и посчитать реальную стоимость в рублях — напишите команде в t.me/nesterov_av, разберём ваш сценарий и поможем с подключением.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Источники
Все цены — из каталога Promptra (1-в-1 с провайдером по курсу ЦБ РФ на 27.05.2026, 71.668 ₽/$); первоисточники цен провайдеров можно перепроверить:
- OpenAI API Pricing — GPT-5.5, GPT-5.4 и линейка OpenAI.
- Anthropic Platform Pricing — Claude Opus 4.7, Sonnet 4.6, Haiku 4.5.
- Google Gemini API Pricing — Gemini 3.1 Pro, Flash Lite, Veo 3.1, Nano Banana.
- DeepSeek API Pricing — DeepSeek V4 Pro и промо-условия.
- Alibaba Cloud Model Pricing — Qwen 3.6 Plus.
- Vals.ai Benchmarks — независимый агрегатор бенчмарков для качественных оценок.
- Курс ЦБ РФ на 27.05.2026 — 71.668 ₽/USD, cbr.ru.
Если на момент чтения цены на сайтах провайдеров разойдутся со статьёй — значит, кто-то обновил прайс. Напишите в t.me/nesterov_av, и материал поправим.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.