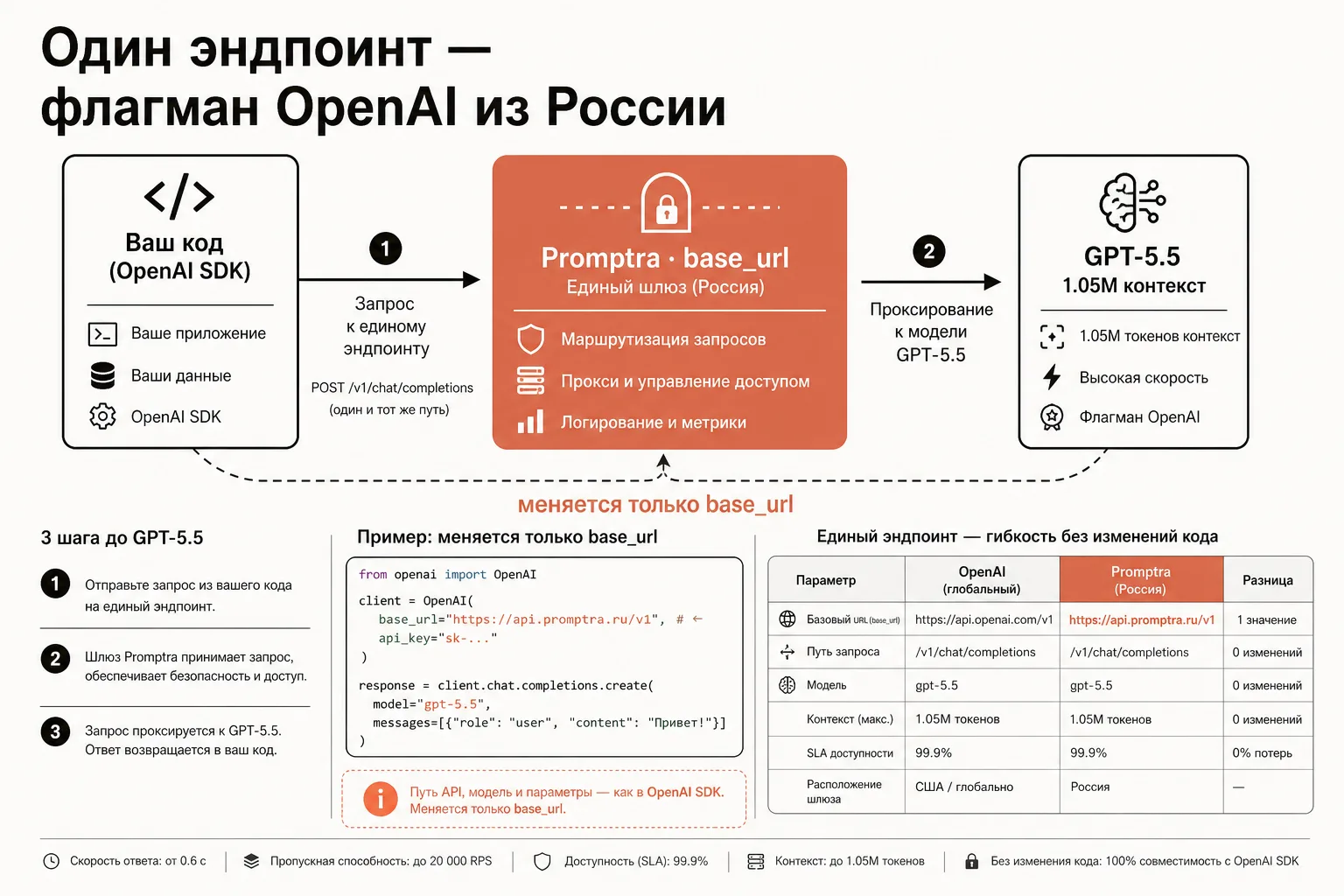
GPT-5.5 — флагманская модель OpenAI, выпущенная 24 апреля 2026 года. Через Promptra она стоит 350 ₽ за 1M входных токенов и 2150 ₽ за 1M выходных — это цена 1-в-1 с прайсом OpenAI ($5 и $30 соответственно) по курсу ЦБ РФ на 27.05.2026 (71.668 ₽/$), без наценки на токены. Контекстное окно — 1 050 000 токенов, максимум на выход — 128 000 токенов. Подключение занимает пять минут: в коде на OpenAI SDK меняется один параметр base_url на https://api.promptra.ru/v1, остальной код остаётся прежним. Оплата идёт на российское юр.лицо с полным пакетом закрывающих документов через ЭДО.
Главный нюанс, который ломает бюджеты на длинных запросах: при входном контексте свыше 272K токенов OpenAI переключает тарификацию на повышенную — 2× за вход и 1.5× за выход на всю сессию. Это не «доплата за лишние токены сверх порога», а смена ставки для всего запроса целиком. Ниже разберём, что это значит на цифрах, когда GPT-5.5 окупается против GPT-5.4 и Claude Opus 4.7, и как подключить модель из России без VPN. Все цены — на 2026-05-28.
Что такое GPT-5.5 и для каких задач
GPT-5.5 — топовая reasoning-модель в линейке OpenAI на конец мая 2026. Это не «чат-модель с улучшениями», а флагман, который OpenAI позиционирует под задачи, где цена ошибки высока: сложный код с длинной цепочкой зависимостей, агентные пайплайны с многошаговым планированием, анализ больших документов, мультимодальные сценарии (на вход принимаются текст и изображения).
В практическом смысле GPT-5.5 — это модель, к которой имеет смысл обращаться, когда более дешёвый GPT-5.4 начинает «срываться»: путает требования в длинном ТЗ, теряет нить в многофайловом рефакторинге, выдаёт правдоподобный, но неверный ответ на вопрос, требующий многошагового рассуждения. На простых задачах — классификация, извлечение полей, короткие ответы FAQ-бота — разница между 5.5 и 5.4 в качестве почти не видна, а в счёте видна сразу: выход GPT-5.5 вдвое дороже.
Ключевые технические характеристики из нашего каталога:
| Параметр | Значение |
|---|---|
| Идентификатор модели | gpt-5.5 |
| Провайдер | OpenAI |
| Дата релиза | 24 апреля 2026 |
| Контекстное окно | 1 050 000 токенов |
| Максимум на выход | 128 000 токенов |
| Модальности входа | текст, изображения |
| Модальности выхода | текст |
| Endpoints | chat, responses |
Миллион токенов контекста — это ориентировочно 700–750 тысяч слов русского текста или примерно 50 000 строк кода. На практике в одно окно влезает кодовая база среднего сервиса целиком, годовой архив переписки или несколько объёмных PDF-договоров. Но, как мы увидим в разделе про тарификацию, «влезает» и «выгодно обрабатывать целиком» — это разные вещи.

Цена GPT-5.5 в рублях: полная таблица
Promptra не накручивает наценку на токены. Стоимость модели равна официальному прайсу OpenAI, пересчитанному в рубли по курсу ЦБ РФ. Сервисная комиссия 5% берётся только при пополнении баланса, а не с каждого запроса, поэтому в расчётах за токены её нет. Базовый прайс OpenAI публикуется на странице моделей OpenAI и общем прайс-листе.
| Тип токенов | Цена OpenAI (USD за 1M) | Цена Promptra (₽ за 1M) |
|---|---|---|
| Вход (input) | $5.00 | 350 ₽ |
| Выход (output) | $30.00 | 2150 ₽ |
Курс пересчёта: 1 USD = 71.668 ₽ (ЦБ РФ на 27.05.2026). Точная арифметика: $5 × 71.668 = 358.34 ₽, $30 × 71.668 = 2150.04 ₽. В каталоге значения округлены до 350 и 2150 ₽ — фактический счёт считается по курсу ЦБ на день пополнения, поэтому в разные дни рублёвая цифра слегка плавает вслед за курсом, а долларовая ставка остаётся фиксированной.
Чтобы понимать порядок расходов, прикинем стоимость типовых сценариев. Соотношение вход/выход в реальной нагрузке обычно смещено в сторону входа (длинный промпт + контекст, короткий ответ), но в reasoning-задачах выход раздувается за счёт «размышлений» модели.
| Сценарий | Вход | Выход | Стоимость |
|---|---|---|---|
| Короткий чат-запрос | 1K | 0.5K | ≈ 1.4 ₽ |
| Анализ документа на 50 страниц | 40K | 4K | ≈ 22.6 ₽ |
| Reasoning-задача с длинным выводом | 10K | 30K | ≈ 68 ₽ |
| RAG-ответ по базе знаний | 80K | 2K | ≈ 32 ₽ |
Цифры приблизительные и зависят от точного количества токенов в ваших данных. Считаются они просто: (входные_токены / 1 000 000 × 350) + (выходные_токены / 1 000 000 × 2150). Реальный расход всегда видно в дашборде по факту запроса, а оценить заранее можно через официальный токенайзер OpenAI — он показывает, на сколько токенов разобьётся конкретный текст.
Нюанс тарификации свыше 272K: как не сжечь бюджет
Это самый важный раздел статьи, потому что именно здесь чаще всего «прилетает» неожиданный счёт. OpenAI указывает в pricing-документации для GPT-5.5 правило: если входной контекст запроса превышает 272 000 токенов, тарификация всей сессии переключается на повышенную ставку — 2× за вход и 1.5× за выход.
Критичный момент: это не «доплата за токены сверх порога». Это смена ставки для всего запроса целиком. Если вы отправили 280K входных токенов, по двойной ставке оплачиваются все 280K, а не только 8K, которые превысили лимит. И выход этого же запроса считается по ставке 1.5×, даже если на выход пришлась пара тысяч токенов.
Посчитаем разницу в рублях:
| Режим | Вход (₽ за 1M) | Выход (₽ за 1M) |
|---|---|---|
| Обычный (вход до 272K) | 350 ₽ | 2150 ₽ |
| Повышенный (вход свыше 272K) | 700 ₽ | 3225 ₽ |
Повышенные ставки — это $10/1M на вход ($5 × 2) и $45/1M на выход ($30 × 1.5), в рублях по курсу ЦБ примерно 700 и 3225 ₽. Иными словами, как только запрос пересекает порог 272K на входе, каждый его токен дорожает: входной вдвое, выходной в полтора раза.
Покажем на конкретном примере, насколько обиден этот «прыжок через порог». Возьмём два почти одинаковых запроса:
| Запрос | Вход | Выход | Ставка входа | Ставка выхода | Стоимость |
|---|---|---|---|---|---|
| A — под порогом | 270K | 5K | 350 ₽ | 2150 ₽ | ≈ 105.3 ₽ |
| B — над порогом | 275K | 5K | 700 ₽ | 3225 ₽ | ≈ 208.6 ₽ |
Разница во входных токенах между запросами — всего 5 тысяч (меньше 2%), а счёт почти удвоился: со 105 до 209 ₽. Причина — переход всего запроса на повышенный тариф.

Как бюджетировать запросы с длинным контекстом
Из этого правила следует несколько практических выводов для тех, кто работает с большими документами или объёмными кодовыми базами:
Держите вход под 272K, если это возможно. Часто полный контекст не нужен: вместо того чтобы отправлять всю кодовую базу, отправьте только релевантные файлы. Вместо целого договора на 400 страниц — раздел, к которому относится вопрос. Грамотный отбор контекста (retrieval) экономит не только токены, но и удерживает запрос в обычной тарифной зоне.
Если вход всё равно большой — считайте по повышенной ставке заранее. Для пайплайнов, где контекст принципиально превышает 272K (анализ длинных юридических документов, обработка больших логов), закладывайте в бюджет ставки 700/3225 ₽ за 1M, а не 350/2150 ₽. Иначе фактический счёт окажется вдвое выше плановых ожиданий.
Разбивайте задачу на части. Два запроса по 200K входных токенов каждый обойдутся в обычную ставку (350 ₽/1M), а один запрос на 400K — в повышенную (700 ₽/1M). При прочих равных два запроса под порогом дешевле одного над порогом примерно вдвое по входу. Это не всегда применимо (если задача требует всего контекста сразу для связности), но там, где документы можно обрабатывать секциями, экономия существенная.
Используйте prompt caching на повторяющемся контексте. Если один и тот же большой блок (системный промпт, справочник, кодовая база) переиспользуется между запросами, кэширование снижает стоимость его повторной отправки. Это отдельная тема, но именно на длинных контекстах эффект максимальный.
Как подключить GPT-5.5 из России: drop-in через OpenAI SDK
Технически GPT-5.5 через Promptra подключается так же, как напрямую через OpenAI — потому что API совместим с OpenAI на уровне протокола. Меняется ровно один параметр: base_url. Ключ OpenAI заменяется на ключ Promptra, всё остальное в коде остаётся прежним.
Python
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx", # ключ Promptra
base_url="https://api.promptra.ru/v1", # единственное изменение
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": "Ты — ассистент инженера."},
{"role": "user", "content": "Объясни разницу между mutex и semaphore."},
],
)
print(response.choices[0].message.content)Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "prm-xxxxxxxxxxxx",
baseURL: "https://api.promptra.ru/v1", // единственное изменение
});
const response = await client.chat.completions.create({
model: "gpt-5.5",
messages: [
{ role: "system", content: "Ты — ассистент инженера." },
{ role: "user", content: "Объясни разницу между mutex и semaphore." },
],
});
console.log(response.choices[0].message.content);Хорошая практика: base_url в переменной окружения
Чтобы не зашивать endpoint в код и иметь возможность переключиться за секунды, держите base_url и ключ в .env:
import os
from openai import OpenAI
# В .env:
# OPENAI_API_KEY=prm-xxxxxxxxxxxx
# OPENAI_BASE_URL=https://api.promptra.ru/v1
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_BASE_URL"],
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Привет"}],
)Проверить, что подключение работает, можно одним curl-запросом без всякого SDK:
curl https://api.promptra.ru/v1/chat/completions \
-H "Authorization: Bearer prm-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.5",
"messages": [{"role": "user", "content": "ping"}]
}'Если в ответ пришёл JSON с полем choices — модель отвечает, можно подключать в продакшен. Почему этот путь надёжнее прямого доступа через VPN и виртуальные карты — мы подробно разобрали в отдельном гайде про OpenAI API в России: там и про блокировки аккаунтов, и про риски карт, и про юридическую сторону.
GPT-5.5 vs GPT-5.4 vs GPT-5.4 mini: когда что выбирать
Самый частый практический вопрос — не «какая модель лучшая», а «какая модель достаточна для моей задачи при минимальной цене». В линейке OpenAI на конец мая 2026 три рабочие точки: флагман 5.5, универсал 5.4 и бюджетный 5.4 mini. Сведём их в таблицу (цены — из нашего каталога, 1-в-1 с прайсом OpenAI по курсу ЦБ).
| Модель | Вход (₽/1M) | Выход (₽/1M) | Контекст | Макс. выход | Роль |
|---|---|---|---|---|---|
| GPT-5.5 | 350 ₽ | 2150 ₽ | 1.05M | 128K | Флагман: сложный reasoning, агенты |
| GPT-5.4 | 170 ₽ | 1070 ₽ | 1.05M | 128K | Универсал: chat, общие задачи |
| GPT-5.4 mini | 50 ₽ | 320 ₽ | 400K | 128K | Массовые запросы, автоматизация |
USD-прайс для справки: GPT-5.5 — $5/$30, GPT-5.4 — $2.5/$15, GPT-5.4 mini — $0.75/$4.5 (источник — прайс-лист OpenAI).
Цифры показывают разрыв наглядно. Выход GPT-5.5 ровно вдвое дороже GPT-5.4 и примерно в 6.7 раза дороже GPT-5.4 mini. На больших объёмах эта разница превращается в десятки и сотни тысяч рублей в месяц.
Берите GPT-5.5, когда: задача требует глубокого многошагового рассуждения, и цена ошибки выше цены токенов. Сложный код с длинными зависимостями, агентные пайплайны с планированием, анализ, где модель должна удерживать в голове много условий одновременно. Если вы заметили, что 5.4 систематически ошибается на вашем классе задач — это сигнал поднять модель.
Берите GPT-5.4, когда: нужен крепкий универсал для большинства задач — генерация и рефакторинг кода средней сложности, развёрнутые ответы, работа с документами, чат-ассистенты для сотрудников. Это «рабочая лошадка», которая закрывает 80% сценариев за половину цены флагмана. Подробный разбор GPT-5.4 будет в отдельной статье про GPT-5.4 API за рубли.
Берите GPT-5.4 mini, когда: объём запросов большой, а каждая задача простая — классификация, извлечение полей, модерация, короткие ответы, обработка очередей. На потоке в миллионы запросов экономия против флагмана драматична: выход дешевле в 6.7 раза. Обратите внимание: у mini контекст 400K, а не 1.05M — для большинства массовых задач этого с запасом, но для обработки очень длинных документов потребуется старшая модель.

GPT-5.5 vs Claude Opus 4.7: флагман против флагмана
Если GPT-5.5 — вершина линейки OpenAI, то её естественный конкурент — Claude Opus 4.7 от Anthropic, флагман в своей линейке. Обе модели нацелены на одни и те же задачи: сложный код, агенты, длинный reasoning. Сравним по цене и характеристикам.
| Параметр | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Вход (₽/1M) | 350 ₽ | 350 ₽ |
| Выход (₽/1M) | 2150 ₽ | 1790 ₽ |
| Вход (USD/1M) | $5.00 | $5.00 |
| Выход (USD/1M) | $30.00 | $25.00 |
| Контекст | 1.05M | 1M |
| Макс. выход | 128K | 128K |
| Особенность тарификации | вход свыше 272K → 2×/1.5× | новый токенайзер: до +35% токенов |
Входная ставка у моделей одинаковая — $5 за 1M. На выходе Claude Opus 4.7 номинально дешевле: 1790 ₽ против 2150 ₽ (на 17% меньше). Но есть два подводных камня, которые делают прямое сравнение «по ставке» обманчивым.
У GPT-5.5 — порог 272K. На запросах с длинным входным контекстом GPT-5.5 переключается на удвоенную ставку, как мы разобрали выше. Claude Opus 4.7 такого скачка не имеет — ставка ровная на всём контексте до 1M. Поэтому на больших входных контекстах Opus 4.7 может оказаться существенно дешевле, несмотря на близкие номинальные цены.
У Claude Opus 4.7 — новый токенайзер. Anthropic в своей pricing-документации предупреждает: Opus 4.7 использует новый токенайзер, который на одном и том же тексте может разбивать его на до 35% больше токенов. То есть номинально более низкая ставка частично съедается тем, что тех же символов получается больше токенов. На русском тексте, который и так токенизируется менее эффективно, чем английский, этот эффект особенно заметен.
Вывод по выбору: на коротких и средних входных контекстах разница между моделями определяется не столько ставкой, сколько тем, как каждая токенизирует именно ваш текст и как справляется с вашим классом задач. На длинных входных контекстах (ближе к сотням тысяч токенов) у GPT-5.5 включается порог 272K, и здесь Claude Opus 4.7 с ровной ставкой может выиграть по деньгам. Практический совет — прогнать обе модели на репрезентативной выборке ваших реальных запросов и сравнить и качество, и фактический счёт. Развёрнутое сравнение всех флагманов мы собрали в обзоре топ-5 LLM 2026.
Лимиты, контекст и максимальный выход
Помимо цены, у GPT-5.5 есть архитектурные лимиты, которые важно учитывать при проектировании:
- Контекстное окно — 1 050 000 токенов. Это суммарный объём «вход + всё, что модель удерживает в рамках запроса». На практике это позволяет загрузить очень крупный объём данных за один вызов — но помните про порог тарификации 272K на входе.
- Максимум на выход — 128 000 токенов. Сколько модель может сгенерировать в одном ответе. 128K выходных токенов — это примерно 90–100 тысяч слов, объём небольшой книги. Для подавляющего большинства задач этого с огромным запасом, но если вы генерируете очень длинные структурированные документы, держите лимит в голове.
- Входные модальности — текст и изображения. GPT-5.5 принимает на вход не только текст, но и изображения (например, скриншоты интерфейсов, диаграммы, фотографии документов). Выход — только текст.
- Endpoints —
chatиresponses. Модель доступна через стандартный chat-completions API (совместимый с OpenAI SDK, как в примерах выше) и через responses API.
Если у вас задача упирается в лимит выхода (нужно сгенерировать документ длиннее 128K токенов) — стандартное решение — разбивать генерацию на части с продолжением контекста, а не пытаться выжать всё в один вызов.
Сколько стоит GPT-5.5 в месяц: прикидка для команды
Чтобы цена в ₽ за миллион токенов превратилась в понятную цифру месячного бюджета, прикинем три профиля нагрузки. Допущения указаны рядом — подставьте свои.
| Профиль | Запросов/мес | Средний вход | Средний выход | Токенов вход/мес | Токенов выход/мес | Стоимость/мес |
|---|---|---|---|---|---|---|
| Небольшой продукт | 50 000 | 3K | 1K | 150M | 50M | ≈ 160 000 ₽ |
| Средняя нагрузка | 300 000 | 5K | 1.5K | 1.5B | 450M | ≈ 1 492 500 ₽ |
| Reasoning-пайплайн | 30 000 | 8K | 8K | 240M | 240M | ≈ 600 000 ₽ |
Расчёт прямой: входные токены за месяц делим на миллион и умножаем на 350 ₽, выходные — на 2150 ₽, складываем. Например, для «небольшого продукта»: 150 × 350 + 50 × 2150 = 52 500 + 107 500 = 160 000 ₽.
Видно, что в reasoning-задачах с большим выходом основной счёт формирует именно output (он дороже входа в 6 с лишним раз). Это ещё один аргумент думать над выбором модели: если на части ваших запросов хватит GPT-5.4, перенос их с 5.5 на 5.4 режет стоимость выхода ровно вдвое. Многие команды строят гибридную схему: дешёвая модель на потоке, флагман — только на запросах, где она реально нужна. Сервисная комиссия Promptra (5%) при этом берётся один раз при пополнении баланса, а не с каждого из этих запросов.
Оплата и документы для юр.лица
Для команд в компаниях важна не только цена токена, но и то, как эти расходы проходят по бухгалтерии. Promptra принимает оплату на российское юр.лицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — с полным пакетом закрывающих документов: договор-оферта, счёт, акт, счёт-фактура, УПД. Документооборот идёт через ЭДО (Диадок, СБИС), что удобно для корпоративной бухгалтерии — документы автоматически проводятся в учётной системе.
Это принципиальное отличие от прямого доступа к OpenAI через VPN и виртуальные карты: при таком сценарии у вас на руках нет закрывающих документов российского формата, расход сложно корректно учесть, а аккаунт живёт до первого бана. Расходы на API без правильно оформленной первички не принимаются к учёту бизнеса. Подробно юридическую и бухгалтерскую сторону мы разобрали в гайде про OpenAI API в России — там и про оферту OpenAI, и про то, как расходы корректно ложатся в учёт компании.
FAQ
Сколько стоит GPT-5.5 в рублях?
Через Promptra — 350 ₽ за 1M входных токенов и 2150 ₽ за 1M выходных. Это прямой пересчёт прайса OpenAI ($5 и $30 за 1M) по курсу ЦБ РФ (71.668 ₽/$ на 27.05.2026), без наценки на токены. Фактический счёт считается по курсу ЦБ на день пополнения баланса. Сервисная комиссия 5% берётся отдельно — только при пополнении, а не с каждого запроса.
Что значит «тарификация свыше 272K токенов»?
Если входной контекст запроса превышает 272 000 токенов, OpenAI переключает всю сессию на повышенную ставку: 2× за вход (700 ₽/1M) и 1.5× за выход (3225 ₽/1M). Важно: по двойной ставке оплачивается весь запрос целиком, а не только токены сверх порога. Поэтому на длинных контекстах стоит либо держать вход под 272K через грамотный отбор контекста, либо заранее закладывать в бюджет повышенные ставки.
Как подключить GPT-5.5 из России без VPN?
Через OpenAI-совместимый endpoint Promptra. В коде на OpenAI SDK меняется один параметр — base_url на https://api.promptra.ru/v1, ключ OpenAI заменяется на ключ Promptra, остальной код не трогается. Модель указывается как gpt-5.5. Прямой доступ через VPN и зарубежные карты не нужен — запросы проксируются легально, а оплата идёт в рублях на юр.лицо.
Чем GPT-5.5 отличается от GPT-5.4?
GPT-5.5 — флагман для сложного reasoning и агентных задач, GPT-5.4 — универсал для большинства повседневных сценариев. По цене разрыв двукратный: выход GPT-5.5 стоит 2150 ₽/1M против 1070 ₽/1M у GPT-5.4. Контекст и максимум выхода у них одинаковые (1.05M и 128K). Брать 5.5 имеет смысл там, где 5.4 систематически ошибается; на простых задачах разница в качестве почти не видна, а в счёте — сразу.
GPT-5.5 или Claude Opus 4.7 — что выбрать?
Входная ставка одинаковая ($5/1M), на выходе Opus 4.7 номинально дешевле (1790 ₽ против 2150 ₽). Но у GPT-5.5 есть порог 272K с удвоением ставки на длинных входах, а у Opus 4.7 — новый токенайзер, который даёт до 35% больше токенов на том же тексте. На длинных входных контекстах часто выгоднее Opus 4.7, на коротких и средних разница определяется тем, как каждая модель токенизирует именно ваш текст и справляется с вашими задачами. Лучший способ выбрать — прогнать обе на реальной выборке и сравнить качество и фактический счёт.
Какой максимальный размер ответа у GPT-5.5?
Максимум на выход — 128 000 токенов за один запрос (примерно 90–100 тысяч слов). Контекстное окно — 1 050 000 токенов суммарно. Если нужен документ длиннее лимита выхода, генерацию разбивают на части с продолжением контекста.
Если вы хотите посчитать стоимость GPT-5.5 под вашу реальную нагрузку или обсудить подключение с закрывающими документами — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Поможем прикинуть бюджет под ваш профиль запросов и подобрать модель — флагман там, где он нужен, и более дешёвую модель там, где её достаточно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.