Qwen 3.6 Plus — многоязычная open-weight модель от Alibaba (линейка Qwen, она же Tongyi Qianwen). Через Promptra она стоит 20 ₽ за 1M входных токенов и 130 ₽ за 1M выходных — это цена 1-в-1 с прайсом DashScope ($0.325 и $1.95 за 1M) по курсу ЦБ РФ на 27.05.2026 (71.668 ₽/$), без наценки на токены. Контекстное окно — 1 000 000 токенов, максимум на выход — 65 536 токенов. Модель сильна в многоязычных задачах (особенно азиатские языки) и в коде, а на входе — одна из самых дешёвых в каталоге. Подключение занимает пять минут: API совместим с OpenAI, в коде меняется один параметр base_url на https://api.promptra.ru/v1. Оплата идёт на российское юр.лицо с полным пакетом закрывающих документов через ЭДО.
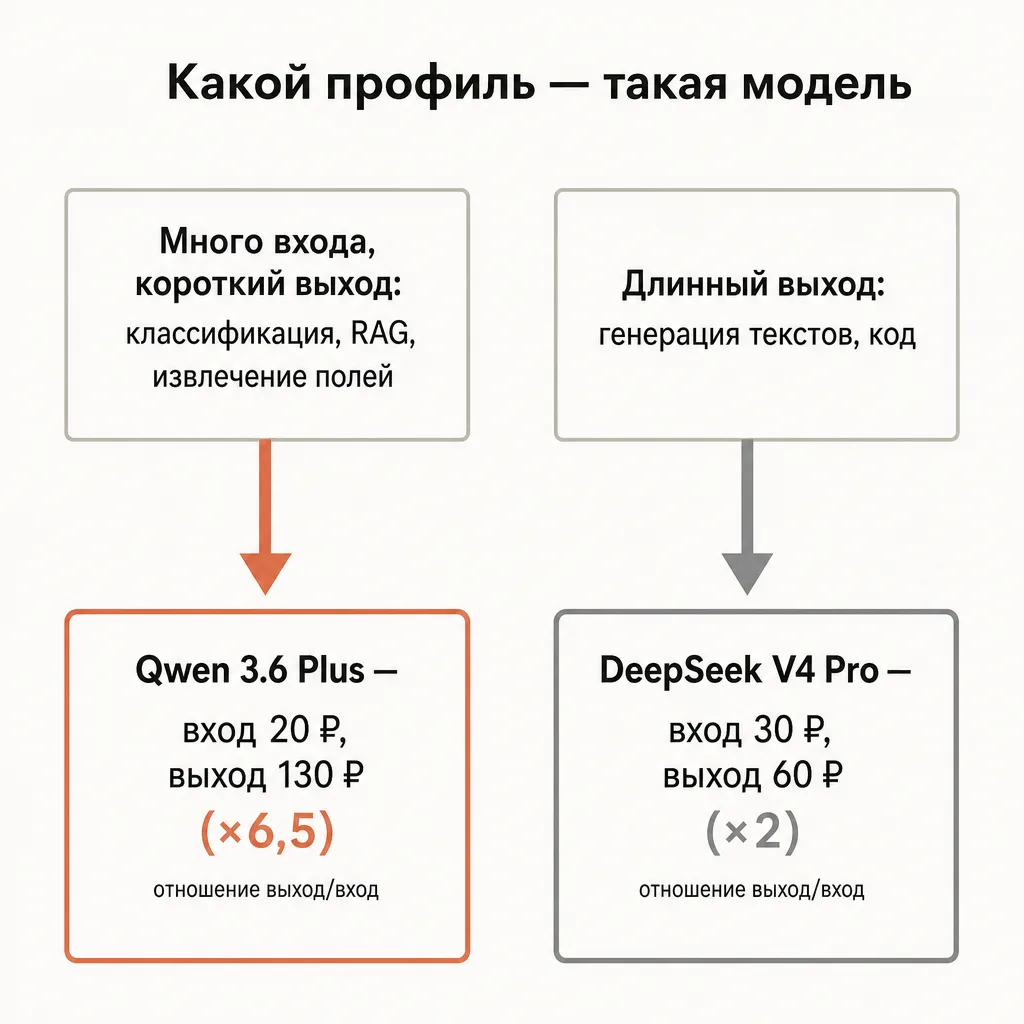
Главное, что выделяет Qwen 3.6 Plus среди дешёвых моделей, — это асимметрия цены: вход стоит копейки (20 ₽/1M), а выход дороже входа в 6.5 раза (130 ₽/1M). Для нагрузок, где много контекста на входе и короткий ответ на выходе — классификация, извлечение полей, RAG-ответы по большой базе — это почти идеальный профиль: вы платите символически за то, что модель «прочитала» гигантский контекст, и совсем немного за короткий вывод. Ниже разберём, где Qwen выигрывает по деньгам у DeepSeek, GLM и флагманов, для каких задач его берут, и как подключить из России без VPN. Все цены — на 29.05.2026.
Что такое Qwen 3.6 Plus и для каких задач
Qwen — это семейство языковых моделей, которое разрабатывает Alibaba Cloud. Линейка существует с 2023 года и за это время выросла в одну из самых заметных open-weight экосистем мира: десятки моделей разного размера, от компактных до флагманских, плюс специализированные версии под код, математику и зрение. Qwen 3.6 Plus — старшая «плюс»-модель текущего поколения, рассчитанная на широкий спектр задач при низкой цене.
Две вещи определяют её характер. Первая — многоязычность. Qwen традиционно силён за пределами английского: китайский, японский, корейский и другие азиатские языки модель обрабатывает заметно лучше, чем большинство западных моделей сопоставимой цены. Русский Qwen тоже поддерживает — для многих повседневных задач (резюмирование, классификация, извлечение данных, генерация описаний) этого достаточно. Если ваш продукт работает с мультиязычным контентом или с азиатскими рынками, Qwen — естественный кандидат.
Вторая — open-weight. Веса Qwen опубликованы под открытой лицензией: модель можно скачать и запускать на своём железе. Для большинства команд это не означает «будем хоститься сами» — это операционно дорого и сложно, — но означает важную вещь: модель не привязана к единственному вендору. Её отдаёт сама Alibaba через DashScope и десятки независимых инференс-провайдеров, и конкуренция держит цену низкой. Именно поэтому Qwen, как и DeepSeek, стоит в разы дешевле проприетарных флагманов.
Ключевые технические характеристики из нашего каталога:
| Параметр | Значение |
|---|---|
| Идентификатор модели | qwen3.6-plus |
| Провайдер | Alibaba Qwen |
| Тип весов | open-weight (открытая лицензия) |
| Контекстное окно | 1 000 000 токенов |
| Максимум на выход | 65 536 токенов |
| Модальности входа | текст |
| Модальности выхода | текст |
| Endpoints | chat |
Миллион токенов контекста — это ориентировочно 700–750 тысяч слов или порядка 50 000 строк кода. В одно окно влезает кодовая база среднего сервиса, объёмный архив документов или длинная история диалога целиком. На фоне таких возможностей цена входа в 20 ₽ за 1M делает Qwen 3.6 Plus инструментом, которым можно «скармливать» большие объёмы контекста, почти не глядя на счёт за вход.

Цена Qwen 3.6 Plus в рублях: полная таблица
Promptra не накручивает наценку на токены. Стоимость модели равна официальному прайсу Alibaba DashScope, пересчитанному в рубли по курсу ЦБ РФ. Сервисная комиссия 5% берётся только при пополнении баланса, а не с каждого запроса, поэтому в расчётах за токены её нет. Базовый прайс публикуется на странице цен Alibaba Cloud Model Studio; рейт по конкретной версии 3.6 Plus также сверяется по листингу openrouter.ai/qwen/qwen3.6-plus.
| Тип токенов | Цена DashScope (USD за 1M) | Цена Promptra (₽ за 1M) |
|---|---|---|
| Вход (input) | $0.325 | 20 ₽ |
| Выход (output) | $1.95 | 130 ₽ |
Курс пересчёта: 1 USD = 71.668 ₽ (ЦБ РФ на 27.05.2026). Точная арифметика: $0.325 × 71.668 ≈ 23.3 ₽, $1.95 × 71.668 ≈ 139.8 ₽. В каталоге значения округлены вниз до 20 и 130 ₽ — фактический счёт считается по курсу ЦБ на день пополнения, поэтому в разные дни рублёвая цифра слегка плавает вслед за курсом, а долларовая ставка остаётся фиксированной.
Отдельно отметим важный нюанс линейки Qwen: у моделей Alibaba исторически тарификация зависит от длины контекста и режима. На официальной странице цен старшие Qwen-модели разбиты на тарифные диапазоны (например, до 256K входных токенов — одна ставка, выше — другая), а «думающий» режим (reasoning) тарифицируется по более высокой выходной ставке, чем обычная генерация. В нашем каталоге для qwen3.6-plus зафиксирована единая ставка 20/130 ₽, которая и применяется к запросам через Promptra; если вы строите пайплайн с очень длинным контекстом или с reasoning-режимом, имеет смысл свериться с официальным прайсом Alibaba по конкретному сценарию.
Чтобы понимать порядок расходов, прикинем стоимость типовых сценариев. Соотношение вход/выход в реальной нагрузке обычно смещено в сторону входа (длинный промпт + контекст, короткий ответ) — а это ровно тот профиль, на котором дешёвый вход Qwen раскрывается максимально.
| Сценарий | Вход | Выход | Стоимость |
|---|---|---|---|
| Короткий чат-запрос | 1K | 0.5K | ≈ 0.085 ₽ |
| Классификация документа | 20K | 0.3K | ≈ 0.44 ₽ |
| RAG-ответ по базе знаний | 80K | 2K | ≈ 1.86 ₽ |
| Анализ кода на 50K токенов | 50K | 4K | ≈ 1.52 ₽ |
Цифры приблизительные и зависят от точного количества токенов в ваших данных. Считаются они просто: (входные_токены / 1 000 000 × 20) + (выходные_токены / 1 000 000 × 130). Реальный расход всегда видно в дашборде по факту запроса. Обратите внимание на масштаб: RAG-ответ с контекстом на 80 тысяч токенов обходится менее чем в 2 ₽ — на флагманах такой же запрос стоил бы десятки рублей.
Где Qwen дешевле всех: разбор асимметрии вход/выход
Главный экономический сюжет Qwen 3.6 Plus — это разрыв между ценой входа и выхода. Вход стоит 20 ₽/1M, выход — 130 ₽/1M, то есть выход дороже входа в 6.5 раза. Это не дефект, а характеристика, которую можно использовать в свою пользу. Сравним соотношения у нескольких дешёвых и средних моделей каталога:
| Модель | Вход (₽/1M) | Выход (₽/1M) | Выход / вход |
|---|---|---|---|
| Qwen 3.6 Plus | 20 ₽ | 130 ₽ | ×6.5 |
| MiniMax M2.7 | 20 ₽ | 80 ₽ | ×4.0 |
| DeepSeek V4 Pro (промо) | 30 ₽ | 60 ₽ | ×2.0 |
| Kimi K2.5 | 40 ₽ | 170 ₽ | ×4.25 |
| GLM 5.1 | 100 ₽ | 310 ₽ | ×3.1 |
Вывод читается прямо из таблицы. Qwen 3.6 Plus и MiniMax M2.7 делят первое место по дешевизне входа (20 ₽/1M), но у Qwen выход дороже. Значит, Qwen оптимален там, где входной контекст большой, а выход короткий: вы платите символическую цену за то, что модель «прочитала» много контекста, и немного — за короткий ответ. И наоборот: если задача генеративная (длинные тексты, развёрнутые ответы, большой output), асимметрия работает против вас, и стоит присмотреться к DeepSeek с его ровным соотношением ×2.
Разложим это на конкретные классы задач:
Идеальный профиль для Qwen (много входа, мало выхода):
- Классификация и маршрутизация. На вход — текст обращения, документа, тикета; на выход — короткая метка категории. Вход может быть длинным, выход — несколько токенов.
- Извлечение полей (extraction). На вход — договор, инвойс, резюме; на выход — структурированный JSON с полями. Выход обычно в разы короче входа.
- RAG-ответы. На вход — вопрос плюс извлечённые фрагменты базы знаний (часто десятки тысяч токенов); на выход — короткий ответ по существу.
- Модерация и скоринг. На вход — контент; на выход — оценка или флаг.
Менее выгодный профиль (много выхода):
- Генерация длинных статей, описаний товаров пачками, развёрнутых отчётов — здесь основной счёт формирует выход, и Qwen теряет часть ценового преимущества. Для таких задач сравните его с DeepSeek (выход 60 ₽/1M в промо-период).
Как подключить Qwen 3.6 Plus из России: drop-in через OpenAI SDK
Технически Qwen 3.6 Plus подключается так же, как любая модель в каталоге, — потому что API Promptra совместим с OpenAI на уровне протокола. Это не случайность: сама Alibaba отдаёт Qwen через OpenAI-совместимый endpoint DashScope (https://dashscope-intl.aliyuncs.com/compatible-mode/v1) и в своей документации прямо рекомендует мигрировать с OpenAI-кода, поменяв ключ, base_url и имя модели. Через Promptra логика та же, но base_url один на все модели каталога, а оплата — в рублях на юр.лицо.
Меняется ровно один параметр — base_url. Ключ заменяется на ключ Promptra, имя модели указывается как qwen3.6-plus, остальной код остаётся прежним.
Python
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx", # ключ Promptra
base_url="https://api.promptra.ru/v1", # единственное изменение
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Ты — ассистент по извлечению данных. Отвечай строго JSON."},
{"role": "user", "content": "Извлеки ИНН и сумму из текста: ..."},
],
)
print(response.choices[0].message.content)Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "prm-xxxxxxxxxxxx",
baseURL: "https://api.promptra.ru/v1", // единственное изменение
});
const response = await client.chat.completions.create({
model: "qwen3.6-plus",
messages: [
{ role: "system", content: "Ты — ассистент по извлечению данных. Отвечай строго JSON." },
{ role: "user", content: "Извлеки ИНН и сумму из текста: ..." },
],
});
console.log(response.choices[0].message.content);Хорошая практика: base_url в переменной окружения
Чтобы не зашивать endpoint в код и иметь возможность переключаться между моделями за секунды, держите base_url и ключ в .env:
import os
from openai import OpenAI
# В .env:
# OPENAI_API_KEY=prm-xxxxxxxxxxxx
# OPENAI_BASE_URL=https://api.promptra.ru/v1
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_BASE_URL"],
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": "Привет"}],
)Проверить, что подключение работает, можно одним curl-запросом без всякого SDK:
curl https://api.promptra.ru/v1/chat/completions \
-H "Authorization: Bearer prm-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.6-plus",
"messages": [{"role": "user", "content": "ping"}]
}'Если в ответ пришёл JSON с полем choices — модель отвечает, можно подключать в продакшен. Удобство OpenAI-совместимого протокола в том, что одну и ту же кодовую базу можно перенаправить с Qwen на DeepSeek или флагман сменой одной строки model — без переписывания интеграции.

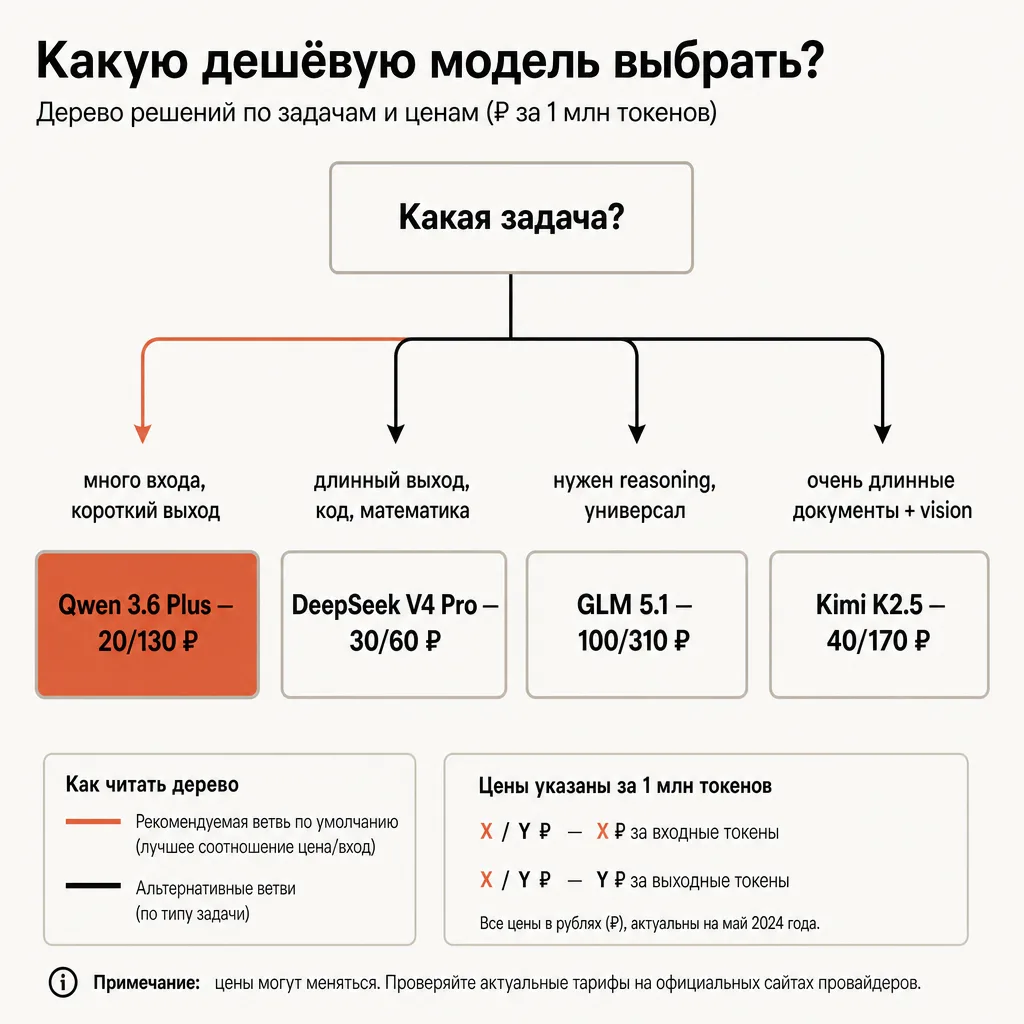
Qwen vs DeepSeek vs GLM: какую дешёвую модель выбрать
В каталоге несколько недорогих open-weight и азиатских моделей, и вопрос «какую взять» сводится не к «какая лучшая», а к «какая дешевле для моего профиля и сильна в нужной мне области». Сведём основных кандидатов в таблицу (цены — из каталога, 1-в-1 с прайсом провайдера по курсу ЦБ).
| Модель | Вход (₽/1M) | Выход (₽/1M) | Контекст | Сильные стороны |
|---|---|---|---|---|
| Qwen 3.6 Plus | 20 ₽ | 130 ₽ | 1M | Многоязычность (азиатские языки), код, дешёвый вход |
| DeepSeek V4 Pro (промо) | 30 ₽ | 60 ₽ | 1M | Код и матлогика, дешёвый и ровный выход |
| GLM 5.1 | 100 ₽ | 310 ₽ | ~203K | Reasoning, сбалансированная универсальная модель |
| MiniMax M2.7 | 20 ₽ | 80 ₽ | ~205K | Дешёвый вход, универсал, азиатская модель |
| Kimi K2.5 | 40 ₽ | 170 ₽ | ~262K | Длинные документы, vision на входе |
USD-прайс для справки: Qwen 3.6 Plus — $0.325/$1.95, DeepSeek V4 Pro — $0.435/$0.87 (промо до 31.05.2026, базовая ставка после ≈ $1.74/$3.48), GLM 5.1 — $1.4/$4.4, MiniMax M2.7 — $0.3/$1.2, Kimi K2.5 — $0.6/$2.5.
Берите Qwen 3.6 Plus, когда: в задаче много входного контекста и короткий выход (классификация, извлечение, RAG, модерация), либо когда важна работа с азиатскими языками. Контекст 1M позволяет загружать огромные объёмы, а вход в 20 ₽/1M делает это почти бесплатным. Это лучший выбор для «прочитать много — ответить коротко».
Берите DeepSeek V4 Pro, когда: задача генеративная (длинный выход) или это код и математика. У DeepSeek ровное соотношение вход/выход (×2) и самый дешёвый выход в этой группе (60 ₽/1M в промо). Важная оговорка: промо-скидка −75% действует до 31 мая 2026, после чего базовая ставка вырастет примерно вчетверо. Подробный разбор — в статье про DeepSeek V4 Pro API за рубли.
Берите GLM 5.1, когда: нужен крепкий универсал с акцентом на reasoning и вы готовы платить за качество ответа больше, чем за Qwen или DeepSeek. GLM дороже (100/310 ₽), но это сбалансированная модель под широкий класс задач. Разбор — в статье про GLM 5.1 (Z.ai) API за рубли.
Берите MiniMax M2.7 или Kimi K2.5, когда: MiniMax — как дешёвая универсальная альтернатива Qwen с более выгодным выходом, но меньшим контекстом (около 205K против 1M). Kimi — когда нужны очень длинные документы (262K контекст) и приём изображений на входе.
Практический совет тот же, что и для флагманов: возьмите репрезентативную выборку ваших реальных запросов, прогоните на двух-трёх кандидатах и сравните не только цену, но и качество ответа на вашем классе задач и языке. OpenAI-совместимый протокол делает такой A/B-тест вопросом смены одной строки model.
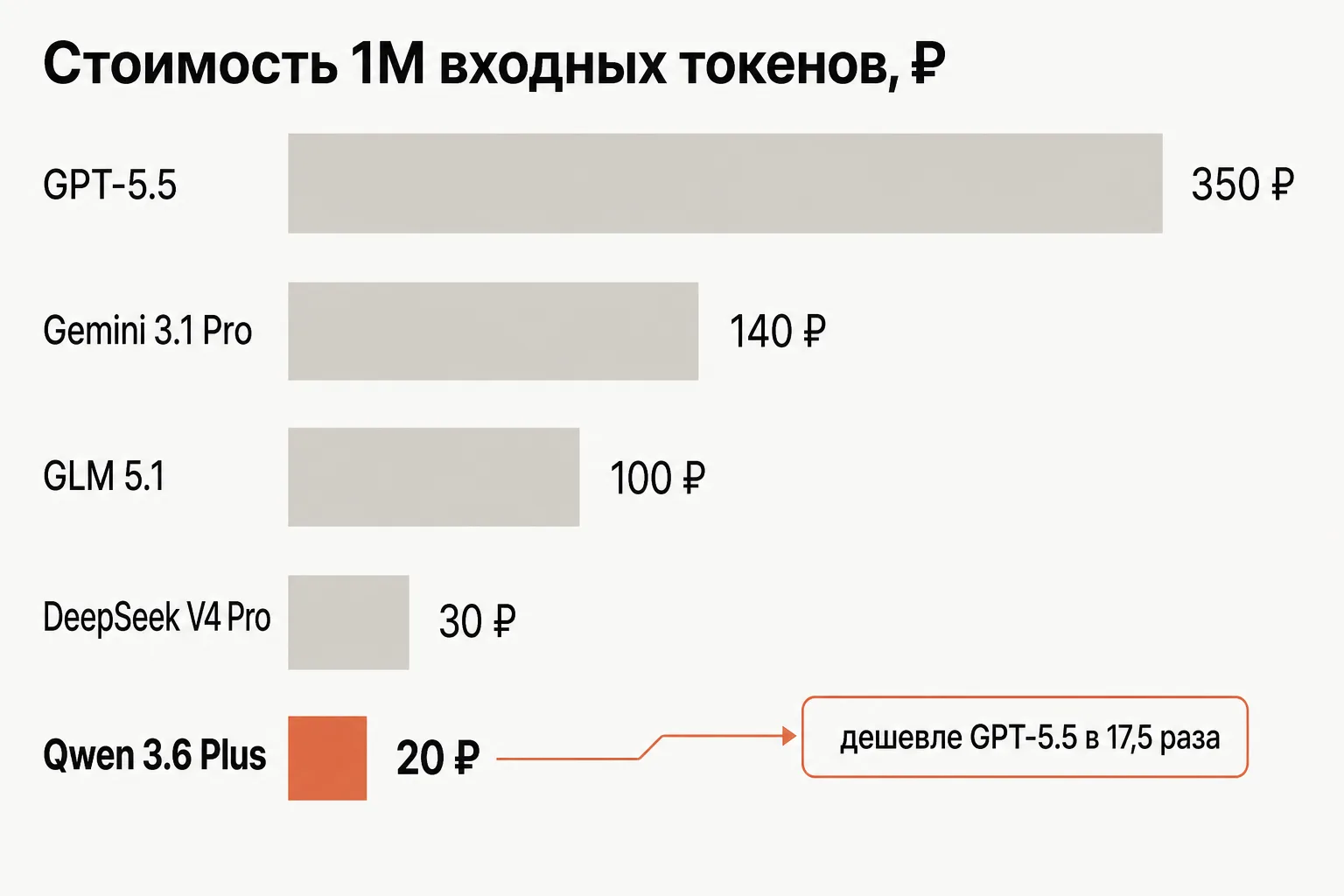
Qwen 3.6 Plus против флагманов: когда экономия оправдана
Полезно понять, насколько именно Qwen дешевле топовых моделей — и где эта экономия имеет смысл, а где нет. Сравним вход и выход с флагманами каталога.
| Модель | Вход (₽/1M) | Выход (₽/1M) | Контекст |
|---|---|---|---|
| Qwen 3.6 Plus | 20 ₽ | 130 ₽ | 1M |
| Gemini 3.1 Pro | 140 ₽ | 860 ₽ | 1M |
| Claude Opus 4.7 | 350 ₽ | 1790 ₽ | 1M |
| GPT-5.5 | 350 ₽ | 2150 ₽ | 1.05M |
Цифры показывают разрыв наглядно. Вход Qwen дешевле GPT-5.5 в 17.5 раза (20 ₽ против 350 ₽), выход — в 16.5 раза (130 ₽ против 2150 ₽). Даже против самого дешёвого из флагманов, Gemini 3.1 Pro, Qwen дешевле в 7 раз по входу и в 6.6 раза по выходу. При этом контекст у Qwen такой же — 1M токенов.
Значит ли это, что Qwen всегда выгоднее? Нет. Разница в цене отражает разницу в назначении. Флагманы (GPT-5.5, Claude Opus 4.7) берут там, где цена ошибки выше цены токенов: сложный многошаговый reasoning, агентные пайплайны с планированием, код с длинными цепочками зависимостей. На таких задачах дешёвая модель может «срываться» — путать требования, терять нить, выдавать правдоподобный, но неверный ответ, — и тогда экономия на токенах оборачивается потерями на исправлении ошибок.
Qwen 3.6 Plus раскрывается на массовых задачах средней сложности, где важен объём и цена за единицу, а не предельное качество рассуждения: обработка очередей, классификация потока обращений, извлечение данных из тысяч документов, RAG-ответы. На потоке в миллионы запросов 17-кратная разница в цене входа превращается в принципиально иной порядок расходов. Многие команды строят гибридную схему: Qwen или DeepSeek на потоке простых и средних задач, флагман — точечно, только на запросах, где он реально нужен. Развёрнутое сравнение всех моделей мы собрали в обзоре топ-5 LLM 2026.
Лимиты, контекст и максимальный выход
Помимо цены, у Qwen 3.6 Plus есть архитектурные лимиты, которые важно учитывать при проектировании:
- Контекстное окно — 1 000 000 токенов. Это суммарный объём «вход + всё, что модель удерживает в рамках запроса». Один из крупнейших контекстов в каталоге наравне с флагманами — позволяет загрузить очень большой объём данных за один вызов.
- Максимум на выход — 65 536 токенов. Сколько модель может сгенерировать в одном ответе. Это вдвое меньше, чем у флагманов (у GPT-5.5 и Claude — 128K), но 65K токенов — это порядка 45–50 тысяч слов, объём большой статьи или главы. Для подавляющего большинства задач этого достаточно с запасом; для генерации очень длинных документов лимит держите в голове.
- Модальности — только текст. Qwen 3.6 Plus в нашем каталоге работает с текстом на входе и выходе. Если нужна обработка изображений на входе, смотрите в сторону моделей с vision (например, Kimi K2.5 или флагманы Claude/GPT/Gemini).
- Endpoint —
chat. Модель доступна через стандартный chat-completions API, совместимый с OpenAI SDK, как в примерах выше.
Если задача упирается в лимит выхода (нужно сгенерировать документ длиннее 65K токенов), стандартное решение — разбивать генерацию на части с продолжением контекста, а не пытаться выжать всё в один вызов.
Сколько стоит Qwen 3.6 Plus в месяц: прикидка для команды
Чтобы цена в ₽ за миллион токенов превратилась в понятную цифру месячного бюджета, прикинем три профиля нагрузки — все смещены в сторону «много входа, короткий выход», где Qwen наиболее выгоден. Допущения указаны рядом — подставьте свои.
| Профиль | Запросов/мес | Средний вход | Средний выход | Токенов вход/мес | Токенов выход/мес | Стоимость/мес |
|---|---|---|---|---|---|---|
| Классификация потока | 1 000 000 | 2K | 0.1K | 2B | 100M | ≈ 53 000 ₽ |
| RAG-ассистент | 200 000 | 30K | 1K | 6B | 200M | ≈ 146 000 ₽ |
| Извлечение из документов | 100 000 | 15K | 0.5K | 1.5B | 50M | ≈ 36 500 ₽ |
Расчёт прямой: входные токены за месяц делим на миллион и умножаем на 20 ₽, выходные — на 130 ₽, складываем. Например, для «классификации потока»: 2000 × 20 + 100 × 130 = 40 000 + 13 000 = 53 000 ₽ за миллион запросов в месяц.
Видно, что даже на миллионе запросов с контекстом по 2 тысячи токенов счёт держится в районе 53 тысяч рублей — за тот же объём на GPT-5.5 он измерялся бы сотнями тысяч. Это и есть основной аргумент в пользу Qwen на массовых задачах: при сопоставимом качестве для классификации и извлечения порядок расходов принципиально другой. Сервисная комиссия Promptra (5%) при этом берётся один раз при пополнении баланса, а не с каждого из этих запросов.
Оплата и документы для юр.лица
Для команд в компаниях важна не только цена токена, но и то, как эти расходы проходят по бухгалтерии. Promptra принимает оплату на российское юр.лицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — с полным пакетом закрывающих документов: договор-оферта, счёт, акт, счёт-фактура, УПД. Документооборот идёт через ЭДО (Диадок, СБИС), что удобно для корпоративной бухгалтерии — документы автоматически проводятся в учётной системе.
С Qwen этот аргумент особенно практичен. Прямой доступ к DashScope из России — это зарубежная карта, валютный платёж и отсутствие закрывающих документов российского формата: расход сложно корректно учесть. Через Promptra вы получаете ту же модель по той же цене (1-в-1 с прайсом Alibaba по курсу ЦБ), но платите в рублях и с первичкой, которую без вопросов примет ваша бухгалтерия. Любой бухгалтер и налоговый инспектор смотрят в первую очередь на документы — и здесь у вас полный комплект. Подробно тему закрывающих документов и того, легально ли использовать зарубежные LLM на юрлицо в РФ, мы разобрали в гайде легально ли использовать AI API на юрлицо.
FAQ
Сколько стоит Qwen 3.6 Plus в рублях?
Через Promptra — 20 ₽ за 1M входных токенов и 130 ₽ за 1M выходных. Это прямой пересчёт прайса Alibaba DashScope ($0.325 и $1.95 за 1M) по курсу ЦБ РФ (71.668 ₽/$ на 27.05.2026), без наценки на токены. Фактический счёт считается по курсу ЦБ на день пополнения баланса. Сервисная комиссия 5% берётся отдельно — только при пополнении, а не с каждого запроса.
Чем Qwen 3.6 Plus отличается от DeepSeek?
Обе модели open-weight и дешёвые, но профиль разный. У Qwen очень дешёвый вход (20 ₽/1M) и более дорогой выход (130 ₽/1M) — он оптимален, когда контекста на входе много, а ответ короткий (классификация, RAG, извлечение). У DeepSeek ровное соотношение вход/выход и самый дешёвый выход в группе (60 ₽/1M в промо до 31.05.2026) — он лучше для генеративных задач и силён в коде и математике. Qwen вдобавок сильнее в многоязычии, особенно в азиатских языках.
Поддерживает ли Qwen русский язык?
Да. Qwen — многоязычная модель и поддерживает русский. Его особая сила — азиатские языки (китайский, японский, корейский), но для повседневных русскоязычных задач (резюмирование, классификация, извлечение данных, генерация описаний) качества достаточно. Для задач, где критично предельное качество русского текста, имеет смысл сравнить Qwen на реальной выборке с флагманами.
Как подключить Qwen 3.6 Plus из России без VPN?
Через OpenAI-совместимый endpoint Promptra. В коде на OpenAI SDK меняется один параметр — base_url на https://api.promptra.ru/v1, ключ заменяется на ключ Promptra, остальной код не трогается. Модель указывается как qwen3.6-plus. Прямой доступ к DashScope через зарубежную карту и VPN не нужен — запросы проксируются легально, а оплата идёт в рублях на юр.лицо с закрывающими документами.
Что значит «open-weight» и почему Qwen такой дешёвый?
Open-weight значит, что веса модели опубликованы под открытой лицензией — её можно скачать и запускать на своём железе. Для большинства команд это не повод хоститься самим (это дорого операционно), но это причина низкой цены: модель отдаёт не только сама Alibaba, но и десятки независимых инференс-провайдеров, и конкуренция между ними держит цену низкой. По той же причине дёшев и DeepSeek.
Какой максимальный размер ответа у Qwen 3.6 Plus?
Максимум на выход — 65 536 токенов за один запрос (примерно 45–50 тысяч слов). Контекстное окно — 1 000 000 токенов суммарно. Это вдвое меньше лимита выхода флагманов (128K), но для большинства задач достаточно. Если нужен документ длиннее лимита, генерацию разбивают на части с продолжением контекста.
Если вы хотите посчитать стоимость Qwen 3.6 Plus под вашу реальную нагрузку или обсудить подключение с закрывающими документами — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Поможем прикинуть бюджет под ваш профиль запросов и подобрать модель — дешёвую там, где её достаточно, и флагман там, где он реально нужен.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.