Чтобы сделать чат-бота на нейросети, не нужно обучать свою модель и поднимать GPU-кластер. Достаточно взять готовую LLM — GPT, Claude или Gemini — и обращаться к ней по HTTP через API. Минимальный рабочий чат-бот на GPT — это примерно 15 строк Python: вы отправляете список сообщений в эндпоинт chat/completions, получаете ответ модели и показываете его пользователю. Вся «магия» уже внутри модели; ваша задача как разработчика — собрать вокруг неё тонкий слой: хранить историю диалога, подмешивать системный промпт, выбрать модель под бюджет и подключить транспорт (веб-чат, Telegram-бот, виджет на сайте).
Эта статья — пошаговый инженерный гайд для тех, кто пишет код. Разберём архитектуру чат-бота на нейросети от запроса пользователя до ответа модели, дадим рабочий Python-код с поддержкой контекста диалога, покажем, как gemini-чат-бот и бот на GPT отличаются только идентификатором модели в одном и том же коде, соберём Telegram-бот как реальный пример и посчитаем, во сколько обойдётся каждый запрос в рублях. Цены — из нашего каталога на 2026-05-29, без наценки на токены, оплата на юрлицо в рублях с закрывающими документами. Поехали.
Что такое чат-бот на нейросети через API
Чат-бот на нейросети — это приложение, которое принимает текст от пользователя, отправляет его большой языковой модели (LLM) и возвращает сгенерированный ответ. Слово «через API» здесь ключевое: вместо того чтобы держать модель у себя, вы вызываете её как внешний сервис по сети. Провайдер (OpenAI, Anthropic, Google) держит модель на своих серверах, а вы платите за токены — единицы текста, которые модель прочитала на входе и сгенерировала на выходе.
Принципиальное отличие чат-бота от одиночного запроса — память диалога. Сама по себе LLM не помнит предыдущие реплики: каждый запрос к API независим (stateless). Чтобы бот «помнил» контекст разговора, ваше приложение должно при каждом новом сообщении отправлять модели всю предыдущую переписку — список сообщений с ролями system, user, assistant. Именно поэтому архитектура чат-бота крутится вокруг управления этим списком: куда его складывать, как обрезать, когда сбрасывать.
Чем чат-бот на API отличается от готовых решений вроде интерфейса ChatGPT:
- Готовый продукт (ChatGPT, Claude.ai) — это веб-приложение для конечного пользователя. Вы не контролируете промпты, не интегрируете в свой продукт, не получаете программный доступ.
- Чат-бот на API — это ваш код. Вы задаёте поведение системным промптом, подключаете свою базу знаний, встраиваете бота в Telegram, на сайт, в CRM, в мобильное приложение — куда угодно, где есть HTTP-клиент.
Для российской команды есть ещё один слой: прямой доступ к API OpenAI, Anthropic и Google из РФ затруднён — карты не проходят, аккаунты блокируются. Поэтому в коде ниже мы обращаемся не напрямую к провайдеру, а через OpenAI-совместимый шлюз с рублёвой оплатой. С точки зрения кода разница — одна строка base_url. Подробно про доступ и оплату мы писали в гайде OpenAI API в России 2026.
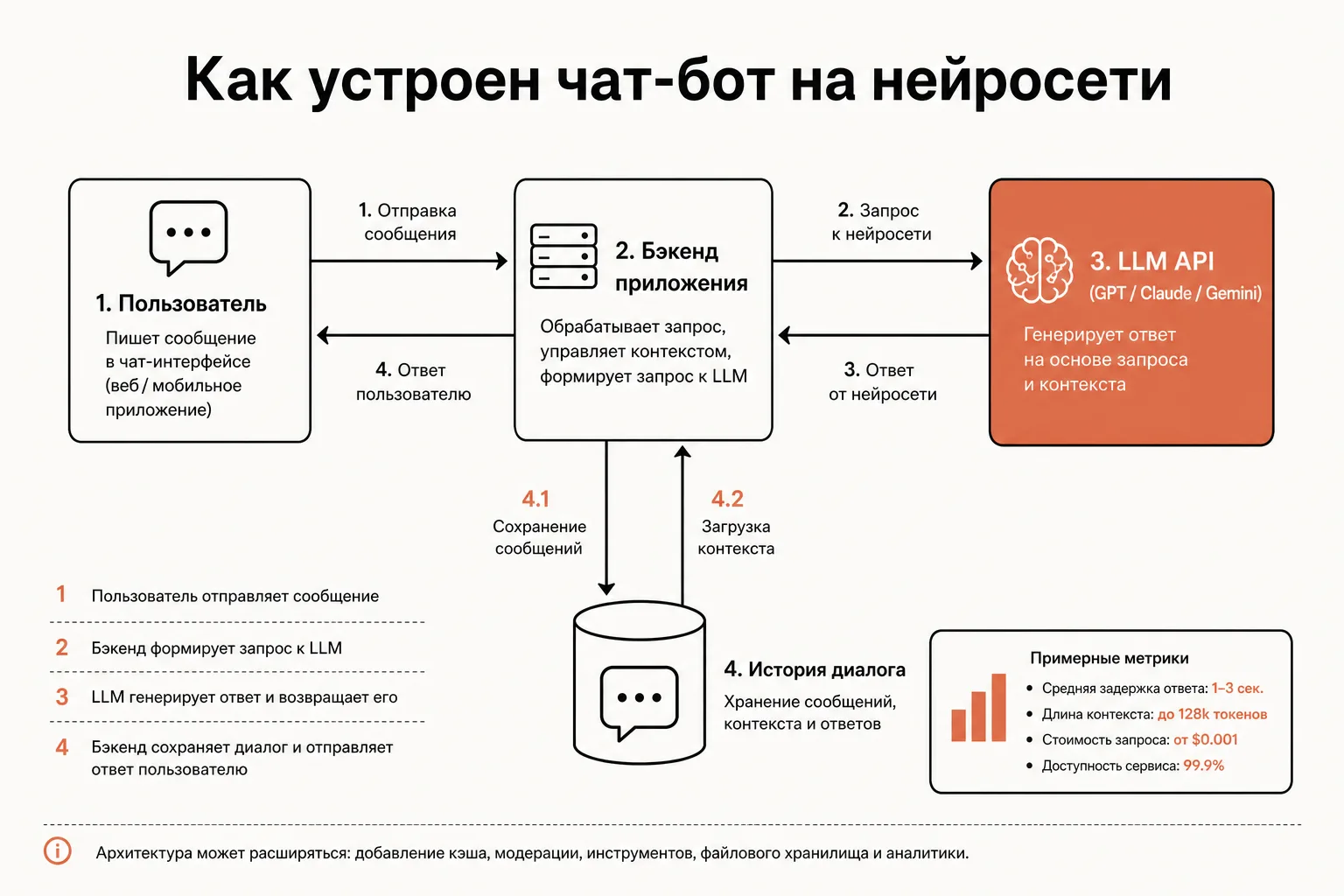
Архитектура чат-бота: от запроса пользователя до ответа модели
Любой чат-бот на нейросети — это три слоя плюс внешний LLM API. Разберём поток одного сообщения.
- Клиент (транспорт). Откуда приходит текст: окно веб-чата, Telegram, виджет на сайте, голосовой ввод. Клиент только передаёт строку пользователя в бэкенд и показывает ответ.
- Бэкенд (ваш код). Сердце бота. Здесь живёт логика: получить сообщение, достать историю диалога этого пользователя, добавить системный промпт, собрать массив
messages, вызвать LLM API, получить ответ, сохранить его в историю, вернуть клиенту. - Хранилище состояния. Где лежит история переписки: в оперативной памяти процесса (для прототипа), в Redis (для продакшена с тысячами пользователей), в Postgres (если нужна постоянная история). Ключ — идентификатор пользователя или чата.
- LLM API. Внешний эндпоинт
chat/completions, в который уходит массив сообщений и возвращается ответ модели.
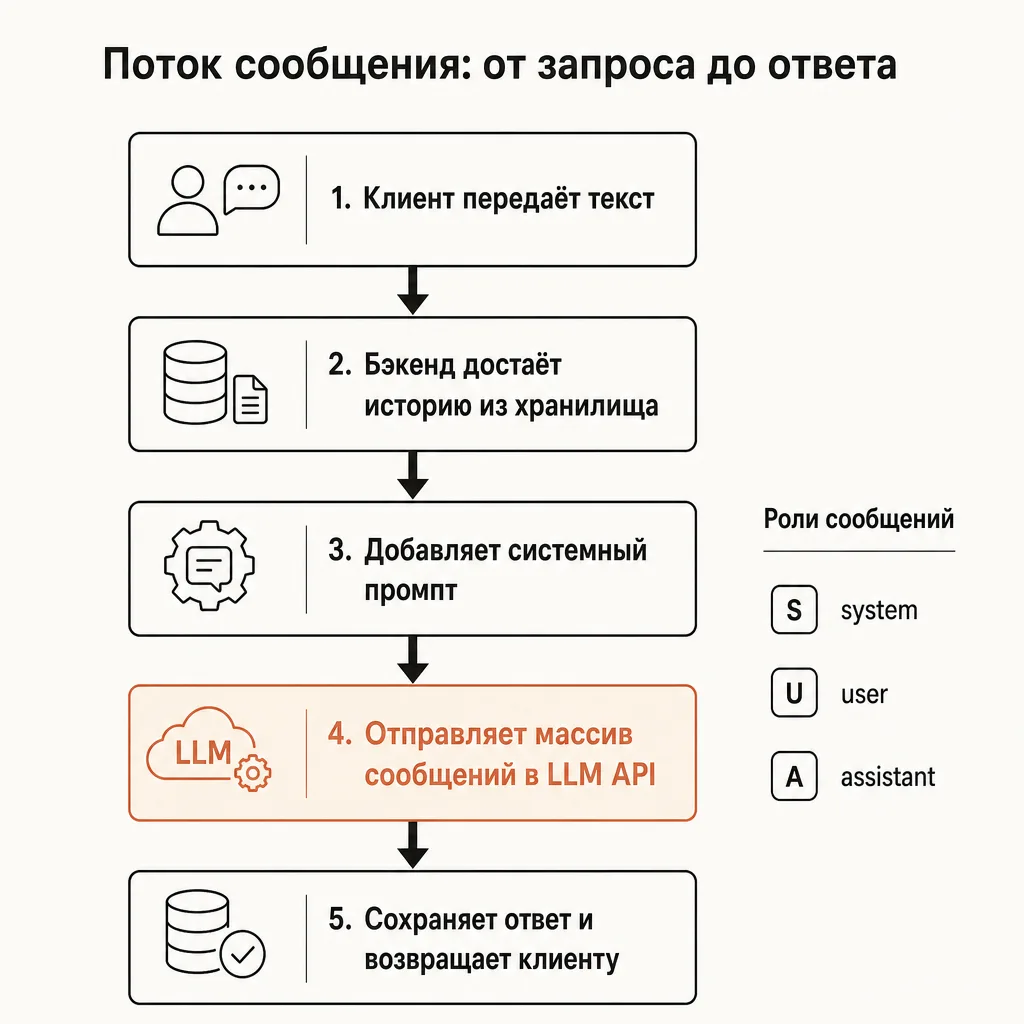
Что важно понять про массив messages — это и есть «состояние» диалога, которое вы каждый раз пересобираете и отправляете модели целиком:
[
{"role": "system", "content": "Ты вежливый ассистент службы поддержки."},
{"role": "user", "content": "Привет, как сбросить пароль?"},
{"role": "assistant", "content": "Здравствуйте! Откройте настройки и..."},
{"role": "user", "content": "А если у меня нет доступа к почте?"}
]Роль system задаёт характер и правила бота, роли user и assistant чередуются — это история. Модель читает весь массив и продолжает диалог следующей репликой assistant. Каждое сообщение в массиве — это входные токены, за которые вы платите. Отсюда главное архитектурное напряжение чат-бота: чем длиннее история, тем «умнее» контекст, но тем дороже каждый запрос. Об управлении этим — отдельный раздел ниже.
Рабочий Python-код: чат-бот с историей диалога
Перейдём к коду. Используем официальную библиотеку openai — она работает с любым OpenAI-совместимым эндпоинтом, в том числе с нашим. Установка:
pip install openaiМинимальный чат-бот без памяти — один запрос, одна реплика:
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx", # ключ из личного кабинета
base_url="https://api.promptra.ru/v1", # OpenAI-совместимый шлюз
)
response = client.chat.completions.create(
model="openai/gpt-5.4",
messages=[
{"role": "system", "content": "Ты лаконичный ассистент. Отвечай по-русски."},
{"role": "user", "content": "Объясни, что такое токен в LLM, в двух предложениях."},
],
)
print(response.choices[0].message.content)Это уже работающий чат-бот на GPT, но без памяти: он ответит на один вопрос и забудет его. Чтобы бот держал контекст диалога, нужно хранить и пополнять массив messages. Вот полноценный консольный чат-бот с историей:
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx",
base_url="https://api.promptra.ru/v1",
)
SYSTEM_PROMPT = "Ты дружелюбный ассистент. Отвечай кратко и по делу, по-русски."
# История диалога. Системный промпт всегда первый.
history = [{"role": "system", "content": SYSTEM_PROMPT}]
def ask(user_text: str) -> str:
# 1. Добавляем реплику пользователя в историю
history.append({"role": "user", "content": user_text})
# 2. Отправляем модели ВСЮ историю целиком
response = client.chat.completions.create(
model="openai/gpt-5.4",
messages=history,
temperature=0.6,
)
# 3. Сохраняем ответ модели — чтобы помнить его в следующем запросе
answer = response.choices[0].message.content
history.append({"role": "assistant", "content": answer})
return answer
if __name__ == "__main__":
print("Чат-бот запущен. Введите 'выход' для завершения.")
while True:
text = input("Вы: ")
if text.strip().lower() in {"выход", "exit", "quit"}:
break
print("Бот:", ask(text))Запустите его, и бот будет помнить разговор: спросите «как меня зовут?» после того как представитесь — он вспомнит, потому что вся переписка уезжает модели при каждом запросе. Три шага в функции ask — это и есть вся суть чат-бота: добавить вопрос, отправить историю, сохранить ответ.
Несколько практических деталей этого кода:
temperature— степень «творчества» модели от 0 до 2. Для поддержки и фактических ответов ставьте 0.2–0.5, для генерации идей и текстов — 0.7–1.0.response.usage— в ответе модель возвращаетprompt_tokensиcompletion_tokens. Это ровно то, за что вы платите. Логируйте их с первого дня, чтобы видеть расход.- Стриминг. Добавьте
stream=True, и ответ придёт по кусочкам (как печатающийся текст в ChatGPT) — это улучшает ощущение скорости. Для веб- и Telegram-ботов почти обязательно.
Ограничение истории: как не сжечь бюджет на длинных диалогах
Наивное хранение всей истории имеет проблему: после 50 реплик каждый запрос тащит модели всю переписку, и вы платите за входные токены снова и снова. Контекст у современных моделей огромный (у GPT-5.4 и Claude Sonnet 4.6 — порядка миллиона токенов), так что технически влезет всё, но платить за это незачем. Две стандартные стратегии:
- Скользящее окно. Храните системный промпт плюс последние N пар «вопрос-ответ» (например, 10). Старые реплики выкидываете. Просто и работает для большинства ботов.
- Суммаризация. Когда история разрастается, отдельным дешёвым запросом просите модель сжать старую часть диалога в короткое резюме и заменяете им хвост истории. Сложнее, но сохраняет смысл длинных разговоров.
Простое скользящее окно поверх кода выше:
MAX_TURNS = 10 # сколько последних пар «вопрос-ответ» помнить
def trim(history: list) -> list:
system = history[:1] # системный промпт сохраняем всегда
dialogue = history[1:]
# оставляем последние MAX_TURNS*2 сообщений (вопрос + ответ)
return system + dialogue[-MAX_TURNS * 2 :]Вызывайте history = trim(history) перед каждым запросом — и расход на входные токены перестанет расти бесконтрольно.
Выбор модели под бюджет: Sonnet, GPT-5.4, DeepSeek или флагман
Главное решение, которое определяет и качество, и счёт вашего чат-бота, — какую модель подключить. Хорошая новость: в OpenAI-совместимом API модель — это просто строка в параметре model. Сменить GPT на Claude или Gemini — поменять один идентификатор, код не трогаете.
Правило выбора простое: дорогую флагманскую модель берут только там, где дешёвая систематически ошибается. Для массовых задач чат-бота — ответы на типовые вопросы, классификация обращений, извлечение полей из текста — разница в качестве между флагманом и средней моделью почти не видна, а в счёте видна сразу. Для сложного многошагового рассуждения, длинного кода, анализа с множеством условий — наоборот, экономия на модели выходит дороже из-за ошибок.
Цены ниже — из нашего каталога на 2026-05-29, рубли за 1 млн токенов, по курсу ЦБ 71.668 ₽/$, без наценки на токены. Для чат-бота обычно важнее output (ответы модели длиннее, чем вопросы):
| Модель | Вход, ₽/1М | Выход, ₽/1М | Контекст | Когда брать в чат-бот |
|---|---|---|---|---|
| Claude Haiku 4.5 | 70 | 350 | 200K | Роутинг, классификация, простые ответы |
| Qwen 3.6 Plus | 20 | 130 | 1M | Массовые ответы, многоязычие, бюджет |
| DeepSeek V4 Pro | 30 | 60 | 1M | Самый дешёвый под объём, код и логика |
| GPT-5.4 Mini | 50 | 320 | 400K | Дешёвый GPT для автоматизации |
| Claude Sonnet 4.6 | 210 | 1070 | 1M | Баланс качества и цены, рабочая лошадка |
| GPT-5.4 | 170 | 1070 | 1.05M | Универсал для чата и общих задач |
| Gemini 3.1 Pro Preview | 140 | 860 | 1M | Сильный reasoning, мультимодал с аудио |
| Claude Opus 4.7 | 350 | 1790 | 1M | Сложный код, агенты, долгое рассуждение |
| GPT-5.5 | 350 | 2150 | 1.05M | Флагман OpenAI для самых тяжёлых задач |
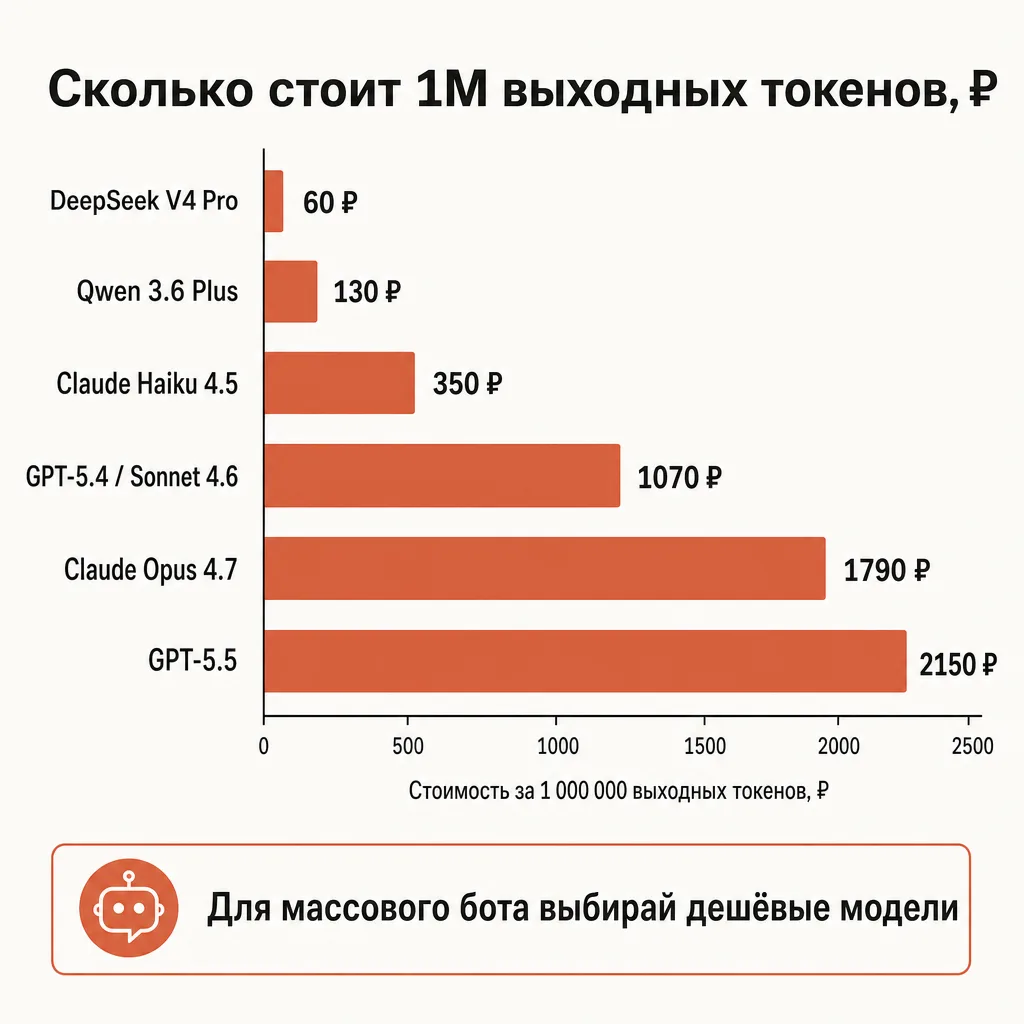
Как читать таблицу под типовые сценарии чат-бота:
- Массовый бот поддержки, FAQ-бот, ассистент в Telegram с большим потоком. Берите дешёвый низ таблицы: DeepSeek V4 Pro, Qwen 3.6 Plus или GPT-5.4 Mini. На простых ответах качества хватает, а 60–320 ₽ за миллион выходных токенов держат счёт под контролем при тысячах диалогов.
- Универсальный бот среднего качества. Claude Sonnet 4.6 и GPT-5.4 — рабочие лошадки: оба 1070 ₽ за миллион выхода, оба тянут связные диалоги, рассуждение и код среднего уровня. С них стоит начинать, если не уверены.
- Сложный ассистент: код-помощник, агент с инструментами, юридический или аналитический бот. Сюда уже флагманы — Claude Opus 4.7, GPT-5.5 или Gemini 3.1 Pro. Платите за глубину только там, где она реально нужна.
Отдельно про DeepSeek V4 Pro: цена 30/60 ₽ — это промо-тариф со скидкой 75%, который действует до 2026-05-31. После окончания акции базовая ставка будет примерно вчетверо выше (около 120/240 ₽ за миллион). Если строите бота на нём — закладывайте базовую цену в расчёты заранее. Подробный разбор каждой флагманской модели — в статьях про GPT-5.5 API за рубли, а также на страницах ChatGPT API, Claude API и Gemini API.
Один код — любая модель: GPT, Claude, Gemini
Поскольку шлюз OpenAI-совместимый, gemini-чат-бот и бот на GPT — это один и тот же код с разным значением model. Можно даже маршрутизировать запросы по сложности: дешёвая модель на простое, флагман на сложное.
# Простой вопрос → дёшево
model = "deepseek/deepseek-v4-pro"
# Нужен сильный reasoning → флагман
model = "openai/gpt-5.5"
# Нужен мультимодал с аудио → Gemini
model = "google/gemini-3.1-pro-preview"
# Код вызова не меняется — только строка model
response = client.chat.completions.create(model=model, messages=history)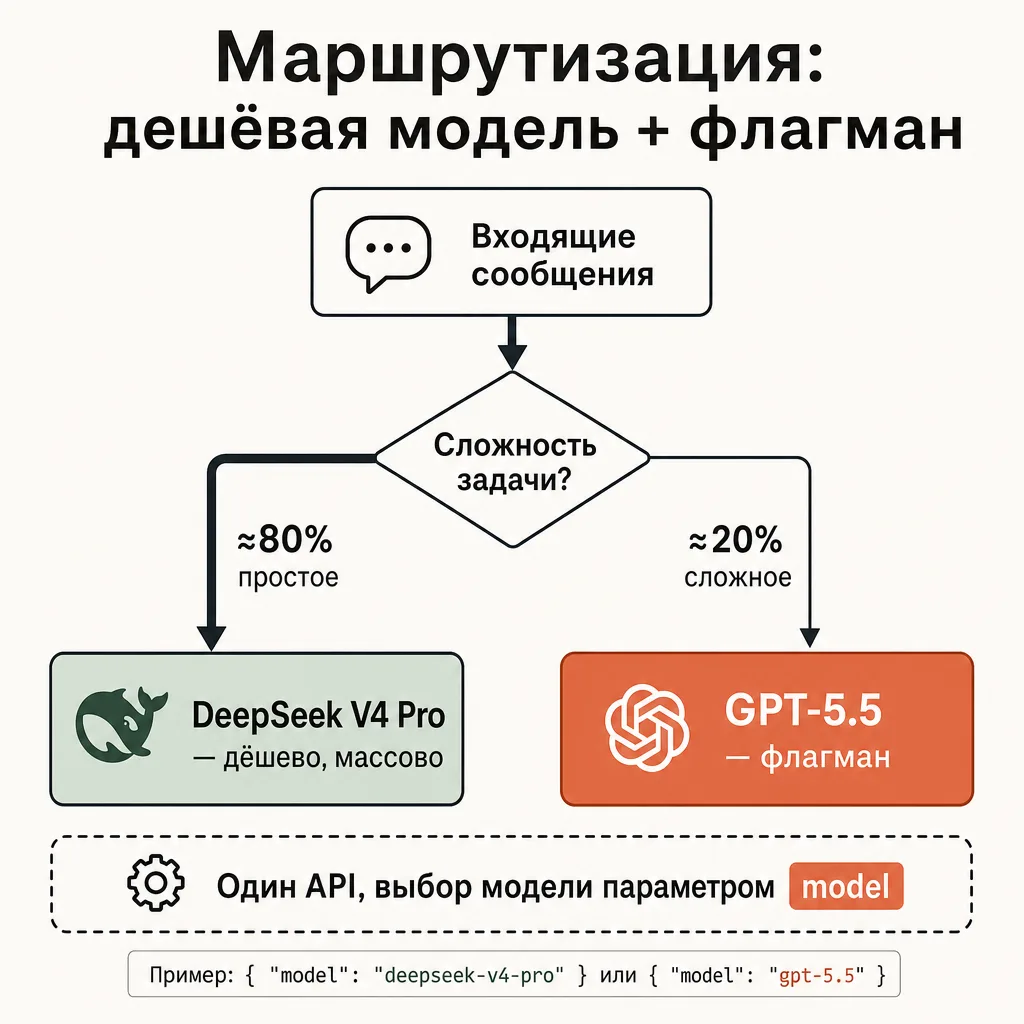
Telegram-бот на нейросети: рабочий пример
Telegram — самый частый транспорт для чат-бота в рунете: не нужно делать фронтенд, аудитория уже там, бесплатный хостинг диалогов. Соберём телеграм-бот на нейросети поверх кода выше. Понадобится библиотека python-telegram-bot и токен бота от @BotFather:
pip install python-telegram-bot openaiimport os
from collections import defaultdict
from openai import OpenAI
from telegram import Update
from telegram.ext import (
Application, CommandHandler, MessageHandler, filters, ContextTypes,
)
client = OpenAI(
api_key=os.environ["LLM_API_KEY"],
base_url="https://api.promptra.ru/v1",
)
SYSTEM_PROMPT = "Ты дружелюбный Telegram-ассистент. Отвечай кратко, по-русски."
MAX_TURNS = 10
# История по каждому чату отдельно: ключ — chat_id
histories: dict[int, list] = defaultdict(
lambda: [{"role": "system", "content": SYSTEM_PROMPT}]
)
async def start(update: Update, ctx: ContextTypes.DEFAULT_TYPE):
histories[update.effective_chat.id] = [
{"role": "system", "content": SYSTEM_PROMPT}
]
await update.message.reply_text("Привет! Я бот на нейросети. Спрашивай.")
async def on_message(update: Update, ctx: ContextTypes.DEFAULT_TYPE):
chat_id = update.effective_chat.id
history = histories[chat_id]
history.append({"role": "user", "content": update.message.text})
# Скользящее окно: системный промпт + последние пары
trimmed = history[:1] + history[1:][-MAX_TURNS * 2 :]
response = client.chat.completions.create(
model="openai/gpt-5.4",
messages=trimmed,
temperature=0.6,
)
answer = response.choices[0].message.content
history.append({"role": "assistant", "content": answer})
await update.message.reply_text(answer)
def main():
app = Application.builder().token(os.environ["TELEGRAM_TOKEN"]).build()
app.add_handler(CommandHandler("start", start))
app.add_handler(MessageHandler(filters.TEXT & ~filters.COMMAND, on_message))
app.run_polling()
if __name__ == "__main__":
main()Запуск:
export TELEGRAM_TOKEN="123456:ABC-DEF..." # от @BotFather
export LLM_API_KEY="prm-xxxxxxxxxxxx" # из личного кабинета
python bot.pyЭто полноценный телеграм-бот с памятью на каждый чат: каждый пользователь ведёт свой диалог, бот помнит контекст в пределах последних десяти реплик. Ключевое отличие от консольной версии — словарь histories с ключом chat_id: у каждого собеседника своя история, они не смешиваются.
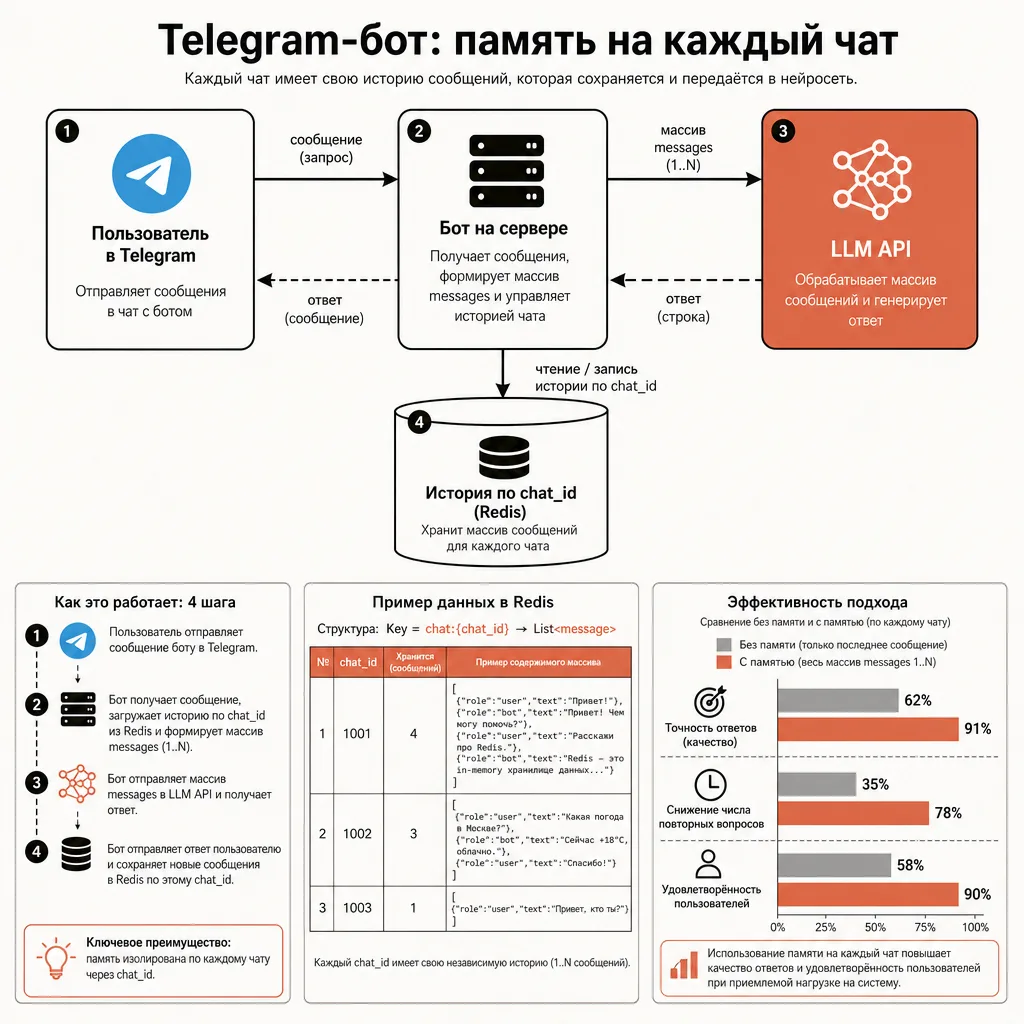
Что добавить для продакшена:
- Перенести историю в Redis. Словарь в памяти теряется при перезапуске и не масштабируется на несколько процессов. Redis с TTL на ключ решает оба вопроса.
- Индикатор набора.
await ctx.bot.send_chat_action(chat_id, "typing")перед запросом — пользователь видит «бот печатает». - Обработка ошибок и лимитов. Оборачивайте вызов API в try/except, на таймауте показывайте вежливое сообщение, логируйте
response.usageдля контроля расхода. - Webhook вместо polling. Для нагруженного бота
run_webhookэффективнее, чемrun_polling.
Сколько стоит чат-бот в месяц: прикидка
Посчитаем расход на реальном примере. Допустим, телеграм-бот поддержки обрабатывает 1000 диалогов в день, в среднем диалог — 6 реплик. Возьмём средний размер: вход (история + промпт) около 800 токенов на запрос, выход около 200 токенов.
На один диалог из 6 реплик: примерно 6 запросов × (800 вход + 200 выход) ≈ 4800 входных + 1200 выходных токенов. За день при 1000 диалогов — около 4.8 млн входных и 1.2 млн выходных токенов. За месяц (30 дней) — примерно 144 млн входных и 36 млн выходных.
Стоимость в месяц по каталожным ценам:
| Модель | Вход 144М | Выход 36М | Итого/мес |
|---|---|---|---|
| DeepSeek V4 Pro (промо) | ~4 320 ₽ | ~2 160 ₽ | ~6 480 ₽ |
| Qwen 3.6 Plus | ~2 880 ₽ | ~4 680 ₽ | ~7 560 ₽ |
| GPT-5.4 Mini | ~7 200 ₽ | ~11 520 ₽ | ~18 720 ₽ |
| GPT-5.4 / Sonnet 4.6 | ~24 480 ₽ | ~38 520 ₽ | ~63 000 ₽ |
Цифры приблизительные — реальный расход зависит от длины ваших промптов и ответов, но порядок виден: на массовом боте выбор модели меняет счёт в десять раз. Для FAQ-бота берите дешёвый низ таблицы; флагман на таком потоке экономически не оправдан. Сократить вход помогает скользящее окно из раздела выше — без него история раздувается и счёт растёт.
К токенам добавляется сервисная комиссия 5% — она удерживается один раз при пополнении баланса (за работу сервиса, эквайринг, биллинг), а не с каждого токена. На сами цены токенов наценки нет: они один в один с провайдером по курсу ЦБ.
Оплата чат-бота на юрлицо в рублях
Для пет-проекта вопрос оплаты не стоит — пополнили баланс картой и работаете. Но если чат-бот — это рабочий инструмент компании или продукт с пользователями, расходы на LLM API нужно проводить по бухгалтерии. Прямой доступ к OpenAI, Anthropic и Google из России для этого не подходит: оплата идёт через зарубежные карты без нормальных закрывающих документов, а аккаунты нестабильны.
У нас оплата идёт на юрлицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — в рублях, с полным пакетом первичных документов: договор-оферта, счёт, акт, счёт-фактура и УПД. Документооборот ведём через ЭДО (Диадок, СБИС), так что закрывающие попадают прямо в вашу учётную систему. Расходы на API чат-бота корректно учитываются как услуги, а не висят серой выплатой на сотруднике. Про юридическую сторону подробно — в статье Легально ли использовать OpenAI/Claude на юрлицо в РФ.
С технической стороны это ничего не меняет: тот же OpenAI-совместимый API, тот же код, одна строка base_url. Вы просто получаете предсказуемый доступ к моделям и нормальные документы для бухгалтерии.
FAQ
Как сделать чат-бота на нейросети с нуля?
Возьмите готовую модель (GPT, Claude или Gemini) и обращайтесь к ней по API — обучать свою не нужно. Минимальный чат-бот на Python — около 15 строк: установите библиотеку openai, создайте клиент с вашим ключом и base_url, отправьте список сообщений в chat.completions.create, покажите ответ. Чтобы бот помнил диалог, храните массив messages и пополняйте его репликами пользователя и модели при каждом запросе. Готовый рабочий код — в разделах выше.
Какая нейросеть лучше для чат-бота?
Зависит от задачи и бюджета. Для массовых ботов (FAQ, поддержка, классификация) хватает дешёвых моделей: DeepSeek V4 Pro (60 ₽ за 1М выхода), Qwen 3.6 Plus (130 ₽) или GPT-5.4 Mini (320 ₽). Для универсального бота среднего качества — Claude Sonnet 4.6 или GPT-5.4 (оба 1070 ₽). Для сложных ассистентов с кодом и многошаговым рассуждением — флагманы Claude Opus 4.7, GPT-5.5 или Gemini 3.1 Pro. Правило: флагман берут только там, где дешёвая модель систематически ошибается.
Как сделать чат-бота на GPT в Telegram?
Соберите бота из двух частей: библиотека python-telegram-bot принимает сообщения из Telegram, а библиотека openai отправляет их модели. Для каждого чата храните отдельную историю диалога с ключом chat_id, чтобы пользователи не мешали друг другу. Полный рабочий пример телеграм-бота на нейросети с памятью на каждый чат — в разделе «Telegram-бот на нейросети» выше. Токен бота берётся у @BotFather, ключ к API — в личном кабинете.
Как чат-бот запоминает контекст диалога?
Сама модель не помнит ничего — каждый запрос к API независим. Память реализует ваше приложение: оно хранит массив сообщений (system, user, assistant) и при каждом новом вопросе отправляет модели всю предыдущую переписку целиком. Модель читает историю и продолжает диалог. Чтобы не платить за бесконечно растущую историю, применяют скользящее окно (хранить последние N пар реплик) или суммаризацию старой части диалога.
Сколько стоит чат-бот на нейросети через API?
Платите только за токены — текст на входе и выходе. Для бота на 1000 диалогов в день на дешёвой модели (DeepSeek, Qwen) расход — порядка 6 500–7 500 ₽ в месяц; на универсальной (GPT-5.4, Sonnet 4.6) — около 63 000 ₽. Цифры зависят от длины промптов и ответов; точную прикидку с разбивкой смотрите в разделе «Сколько стоит чат-бот в месяц». Цены на токены — без наценки, по курсу ЦБ; сервисная комиссия 5% берётся только при пополнении баланса.
Можно ли менять модель в чат-боте без переписывания кода?
Да. В OpenAI-совместимом API модель — это просто строка в параметре model. Чтобы переключить бота с GPT на Claude или Gemini, поменяйте одно значение (openai/gpt-5.4 → anthropic/claude-sonnet-4.6 → google/gemini-3.1-pro-preview), остальной код не трогаете. Это позволяет маршрутизировать запросы по сложности: дешёвую модель на простые вопросы, флагман на сложные.
Если хотите обсудить подключение, подобрать модель под нагрузку вашего чат-бота или посчитать стоимость под конкретный сценарий — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Без эскалаций и саппорта первой линии — технические вопросы решаются за один разговор.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.