Сократить расходы на LLM API позволяют пять приёмов, которые работают независимо от провайдера и складываются между собой: (1) выбор модели под задачу — дешёвая модель там, где её хватает, флагман только там, где он нужен (разница в цене доходит до 35 раз); (2) prompt caching — повторно отправляемый контекст оплачивается со скидкой до 90%; (3) маршрутизация запросов — простые запросы идут на дешёвую модель, сложные — на флагман; (4) контроль длины контекста и выхода — выходные токены кратно дороже входных, и каждый сэкономленный токен ответа снижает счёт; (5) батчинг — асинхронная обработка большими пачками со скидкой 50%. На вопрос «сколько стоит нейросеть по API» точного универсального ответа нет — стоимость определяется именно этими решениями, а не самим фактом подключения модели.
Ниже — каждый приём с расчётами в рублях по нашему каталогу. Цены у Promptra идут 1-в-1 с прайсом провайдера по курсу ЦБ РФ (71.668 ₽/$ на 27.05.2026), без наценки на токены, поэтому вся экономия от оптимизации достаётся вам целиком, а не съедается посреднической надбавкой. Сервисная комиссия 5% берётся отдельно — только при пополнении баланса, а не с каждого запроса. Все цифры — на 2026-05-29.
Из чего складывается стоимость LLM API
Прежде чем экономить, нужно понимать, за что вы платите. У текстовых моделей счёт состоит из двух частей, и они тарифицируются по разным ставкам:
- Входные токены (input) — всё, что вы отправляете модели: системный промпт, история диалога, контекст, документы, инструкции. Это ставка за «прочитанное».
- Выходные токены (output) — то, что модель сгенерировала в ответ. Эта ставка почти всегда существенно выше входной.
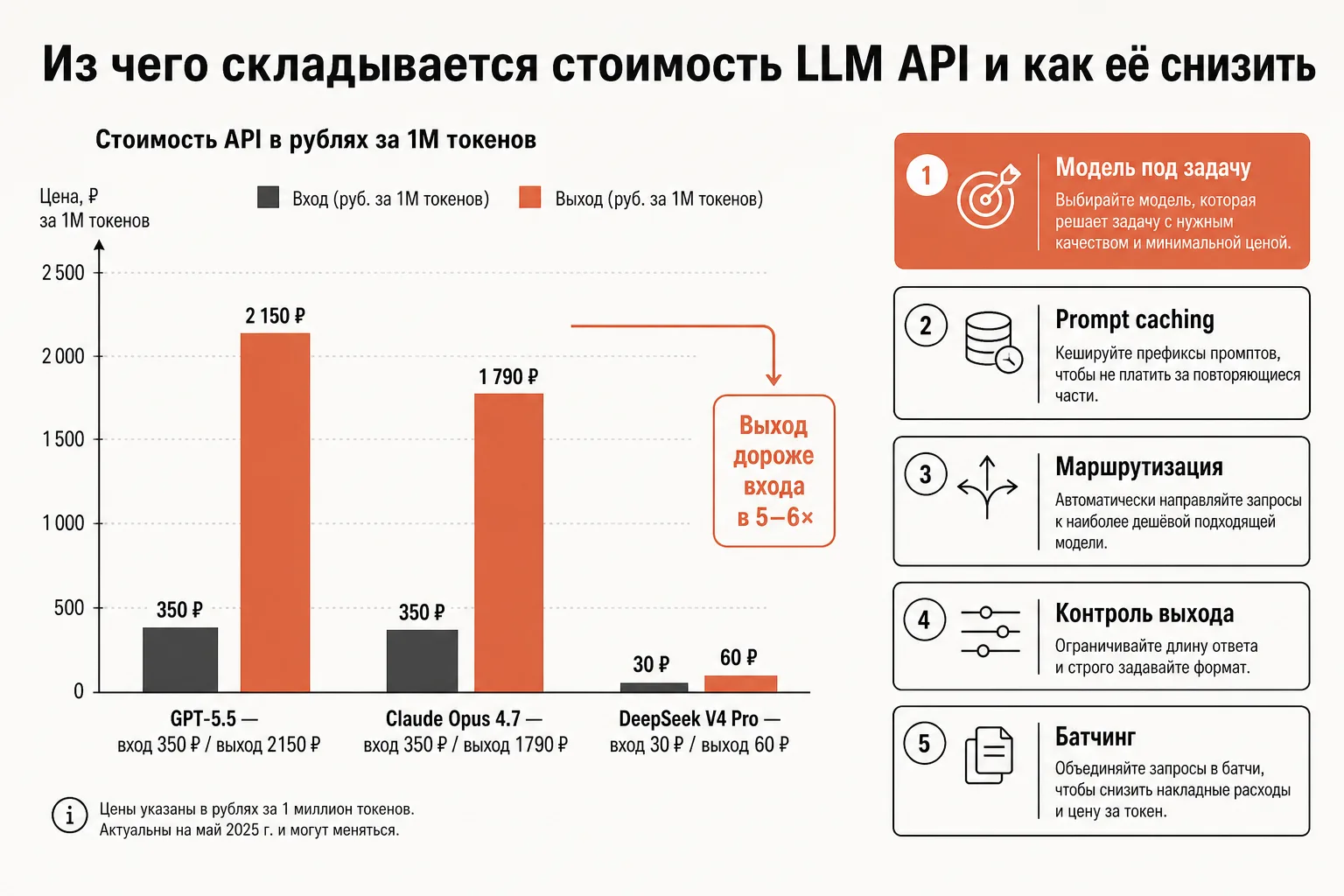
Разрыв между ставками — ключ к пониманию счёта. Возьмём флагманы из нашего каталога:
| Модель | Вход (₽/1M) | Выход (₽/1M) | Во сколько раз выход дороже входа |
|---|---|---|---|
| GPT-5.5 | 350 ₽ | 2150 ₽ | ≈ 6.1× |
| Claude Opus 4.7 | 350 ₽ | 1790 ₽ | ≈ 5.1× |
| Claude Sonnet 4.6 | 210 ₽ | 1070 ₽ | ≈ 5.1× |
| DeepSeek V4 Pro | 30 ₽ | 60 ₽ | 2× |
У большинства флагманских моделей выход дороже входа в 5–6 раз. Практический вывод напрашивается сам: расходы обычно растут не от того, что вы много отправляете, а от того, что модель много генерирует. Длинный, многословный ответ модели бьёт по счёту сильнее, чем длинный контекст на входе. Именно поэтому контроль выхода (приём 4) и выбор более скромной модели для генерации (приёмы 1 и 3) дают самый заметный эффект.
Токен — это примерно 3–4 символа русского текста или около ¾ английского слова. Миллион токенов — это ориентировочно 700–750 тысяч слов. Прикинуть, на сколько токенов разобьётся конкретный текст, можно через официальный токенайзер OpenAI — это полезно делать до того, как отправлять данные в прод, чтобы оценить порядок расходов заранее.
Приём 1. Выбирайте модель под задачу
Это самый сильный рычаг экономии, и применить его проще всего. В каталоге есть модели на любой бюджет, и разница между ними — не проценты, а порядки. Сравним стоимость 1 миллиона выходных токенов у моделей разного класса:
| Модель | Класс | Вход (₽/1M) | Выход (₽/1M) |
|---|---|---|---|
| GPT-5.5 | флагман OpenAI | 350 ₽ | 2150 ₽ |
| Claude Opus 4.7 | флагман Anthropic | 350 ₽ | 1790 ₽ |
| Claude Sonnet 4.6 | универсал | 210 ₽ | 1070 ₽ |
| GPT-5.4 | универсал | 170 ₽ | 1070 ₽ |
| Kimi K2.5 | бюджет | 40 ₽ | 170 ₽ |
| Qwen 3.6 Plus | бюджет | 20 ₽ | 130 ₽ |
| MiniMax M2.7 | бюджет | 20 ₽ | 80 ₽ |
| DeepSeek V4 Pro | бюджет | 30 ₽ | 60 ₽ |
| MiMo V2 Pro | бюджет | 10 ₽ | 20 ₽ |
Выход у DeepSeek V4 Pro стоит 60 ₽ за 1M токенов против 2150 ₽ у GPT-5.5. Это разница примерно в 35 раз на выходных токенах. То есть один и тот же объём генерации на флагмане OpenAI и на DeepSeek различается по цене в десятки раз. (Важный нюанс: для DeepSeek V4 Pro действует промо-скидка 75% до 31 мая 2026; после неё базовая ставка вырастет ориентировочно до $1.74/$3.48 за 1M — это видно в официальном прайсе DeepSeek. Но даже базовая ставка DeepSeek остаётся в разы дешевле флагманов.)
Ключевая ошибка, на которой команды теряют деньги, — использовать флагман по умолчанию для всего. На практике большая часть запросов в типичном продукте — это простые операции: классификация, извлечение полей из текста, модерация, короткие ответы FAQ-бота, разметка. На таких задачах разница в качестве между флагманом и бюджетной моделью почти не видна, а в счёте видна сразу — в десятки раз.
Ориентир по выбору:
- Простые массовые задачи (классификация, извлечение, модерация, теги, короткие ответы) → бюджетные модели: DeepSeek V4 Pro, Qwen 3.6 Plus, MiMo V2 Pro, Gemini 3.1 Flash Lite, Claude Haiku 4.5. Здесь важны цена и скорость, а не пиковый интеллект.
- Универсальные задачи (генерация и рефакторинг кода средней сложности, развёрнутые ответы, чат-ассистенты, работа с документами) → универсалы: GPT-5.4, Claude Sonnet 4.6. Это «рабочие лошадки», закрывающие большинство сценариев за половину цены флагмана.
- Сложный reasoning (длинные цепочки рассуждений, агентные пайплайны, код с большим числом зависимостей, задачи, где цена ошибки высока) → флагманы: GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro.
DeepSeek особенно силён в коде и математической логике при копеечной цене — подробный разбор есть в статье про DeepSeek V4 Pro API за рубли. А обзорное сравнение флагманов и универсалов по задачам и цене мы собрали в материале топ-5 LLM 2026 — он помогает быстро прикинуть, какая модель закроет ваш класс задач без переплаты.
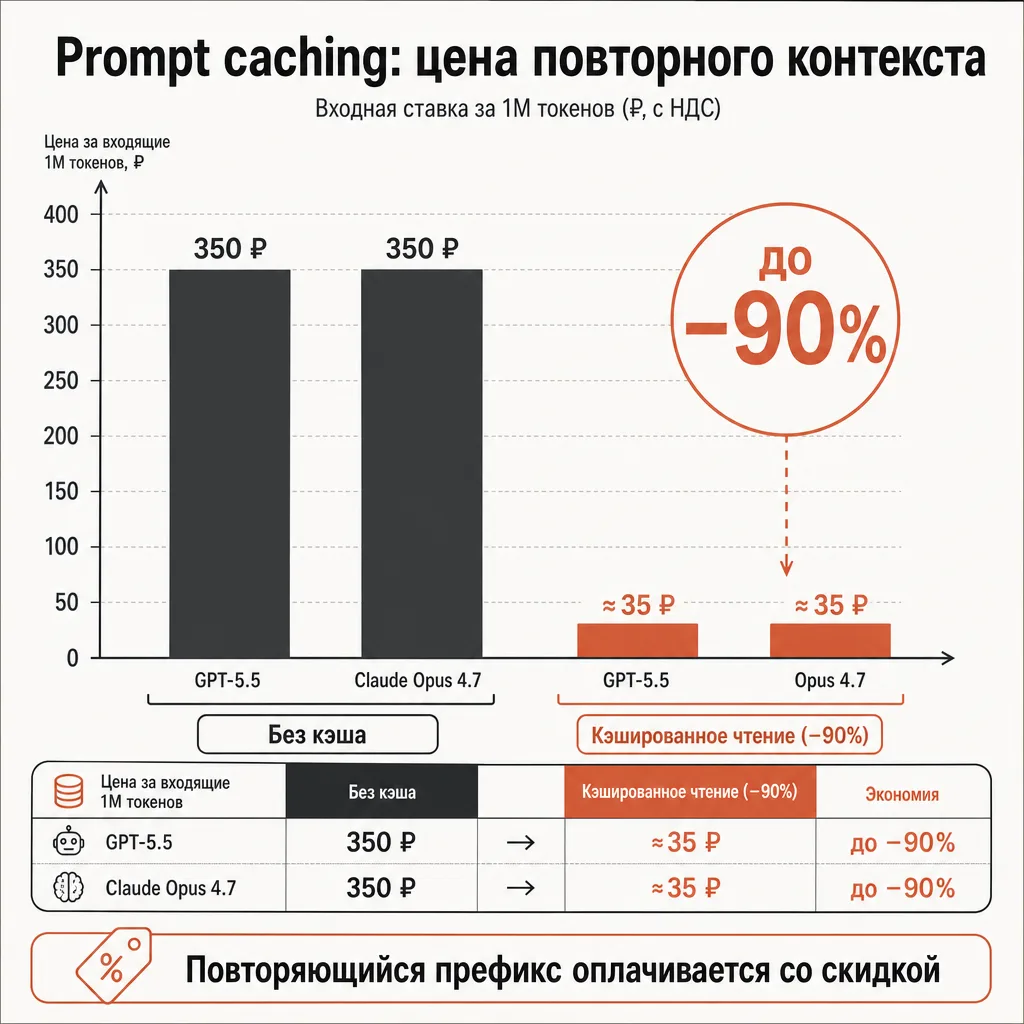
Приём 2. Prompt caching: повторный контекст со скидкой до 90%
Если в ваших запросах раз за разом повторяется один и тот же большой блок — длинный системный промпт, справочник, документация, кодовая база, few-shot-примеры — вы платите за его повторную отправку каждый раз. Prompt caching (кэширование промпта) решает именно эту проблему: провайдер запоминает уже обработанный префикс, и при следующих запросах его повторная подача оплачивается со значительной скидкой.
Цифры по основным провайдерам (со ссылками на первоисточники):
- OpenAI. Кэшированные входные токены тарифицируются с 90% скидкой: для GPT-5.5 это $0.50 за 1M вместо $5, для GPT-5.4 — $0.25 вместо $2.50. Кэширование включается автоматически для достаточно длинных промптов — менять код не нужно. Детали — в руководстве OpenAI по prompt caching и прайс-листе.
- Anthropic (Claude). Чтение из кэша стоит 0.1× от базовой входной ставки (то есть −90%), запись в кэш — 1.25× базовой ставки для 5-минутного TTL или 2× для часового. Минимальная длина кэшируемого блока — 4096 токенов для Opus 4.7 и 1024 токена для Sonnet 4.6 и Haiku 4.5. Источник — документация Anthropic по prompt caching.
- DeepSeek. Context Caching на диске включён по умолчанию для всех, без изменения кода, как указано в документации DeepSeek. Попадания и промахи кэша видны в полях ответа
prompt_cache_hit_tokensиprompt_cache_miss_tokens.
Главное про экономику кэша: выгода тем больше, чем больше повторяющийся контекст и чем чаще к нему обращаются. Чистая выгода появляется, когда стоимость повторных чтений по сниженной ставке перевешивает разовую наценку на запись.
Где кэширование окупается заметнее всего:
- Чат-боты и ассистенты с большим неизменным системным промптом, который шлётся в каждом сообщении.
- RAG-пайплайны, где один и тот же справочный блок (политики, документация, база знаний) подмешивается во множество запросов.
- Агенты и инструменты для кода, держащие в контексте крупную и стабильную часть кодовой базы между шагами.
- Few-shot-промпты с длинным набором примеров перед коротким переменным вопросом.
Чтобы кэш срабатывал, держите неизменную часть промпта (системные инструкции, справочник, примеры) в начале, а переменную (конкретный вопрос пользователя) — в конце. Кэшируется именно общий префикс, поэтому стабильное — наверх, изменчивое — вниз.
Приём 3. Маршрутизация запросов: простое — на дешёвую, сложное — на флагман
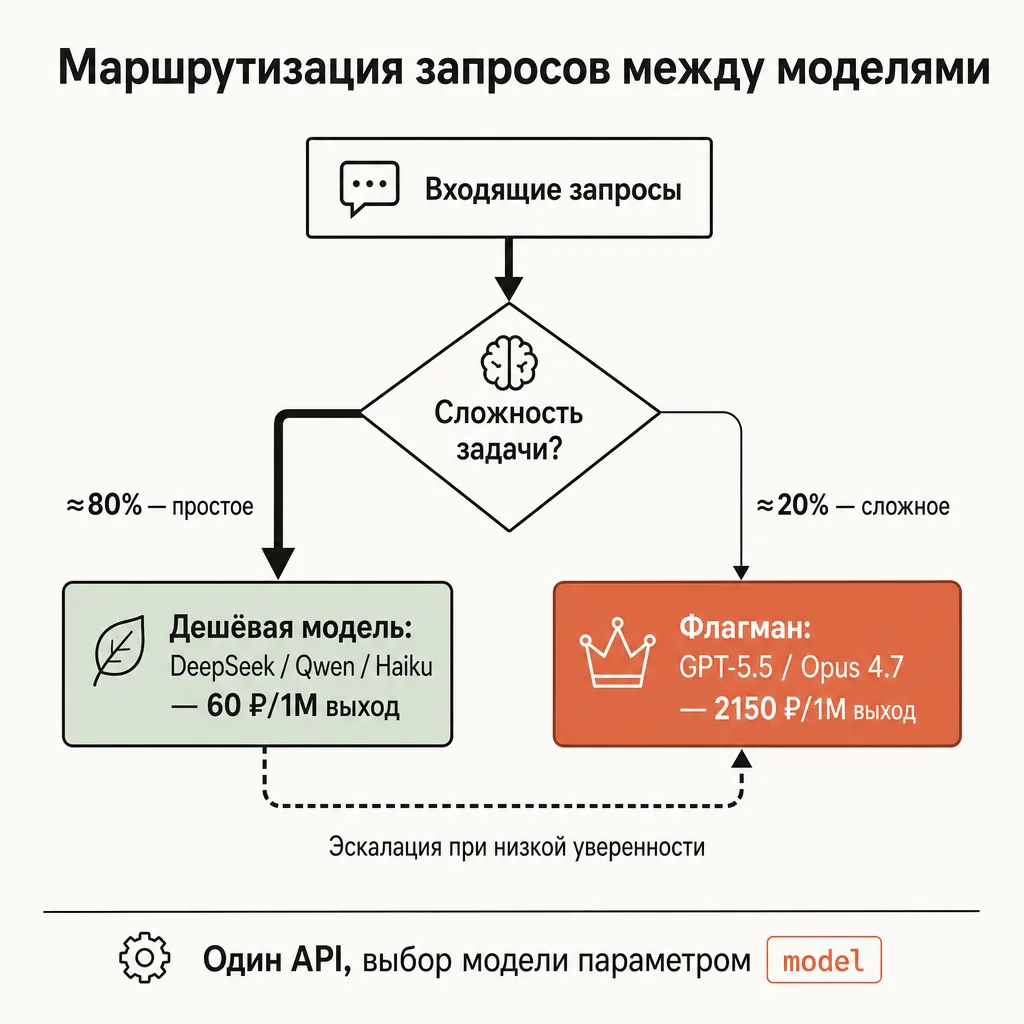
Приём 1 говорит «выбирай правильную модель под задачу». Маршрутизация — это его автоматизация в продакшене: вместо того чтобы гонять весь трафик через одну модель, вы заводите слой, который классифицирует входящий запрос по сложности и направляет его на подходящую модель. Простое — на дешёвую, сложное — на флагман.
Логика обычно такая:
- Триаж. Дешёвая и быстрая модель (или простое правило) оценивает запрос: это короткий типовой вопрос или сложная многошаговая задача?
- Дешёвый путь. Большинство запросов — простые. Их обрабатывает бюджетная модель (DeepSeek, Qwen, Haiku, Gemini Flash Lite). Это основной поток.
- Дорогой путь. Меньшая часть — действительно сложные запросы. Только они идут на флагман (GPT-5.5, Opus 4.7).
- Эскалация. Если дешёвая модель не справилась (низкая уверенность, провал валидации), запрос автоматически переотправляется на флагман.
Эффект на цифрах легко оценить. Допустим, 100 000 запросов в месяц, в среднем 1K входных и 1K выходных токенов на запрос (суммарно 100M вход + 100M выход).
| Стратегия | Распределение | Расчёт выхода (доминирующая часть) | Стоимость выхода/мес |
|---|---|---|---|
| Всё на GPT-5.5 | 100% флагман | 100M × 2150 ₽/1M | ≈ 215 000 ₽ |
| Маршрутизация 80/20 | 80% DeepSeek + 20% GPT-5.5 | 80M × 60 ₽ + 20M × 2150 ₽ | ≈ 47 800 ₽ |
Перенос 80% потока на дешёвую модель срезает расходы на выход с 215 000 до ≈ 47 800 ₽ — экономия примерно 78%, и это только по выходным токенам (на входе картина аналогичная). При этом сложные 20% по-прежнему обрабатываются флагманом, так что качество на трудных запросах не страдает.
Технически у Promptra это делается без отдельной инфраструктуры: все модели доступны через один OpenAI-совместимый endpoint, а выбор модели — это просто значение поля model в запросе. Ваш роутер решает, какую модель подставить, и шлёт запрос на тот же base_url.
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxx",
base_url="https://api.promptra.ru/v1",
)
def route(prompt: str) -> str:
# Простая эвристика: длинные/сложные запросы — на флагман,
# остальное — на дешёвую модель. В проде здесь может быть
# классификатор на бюджетной модели.
if len(prompt) > 4000 or "проанализируй" in prompt.lower():
return "gpt-5.5" # дорогой путь — сложное
return "deepseek/deepseek-v4-pro" # дешёвый путь — массовое
def ask(prompt: str) -> str:
model = route(prompt)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.contentЭто упрощённый пример — в реальном продукте триаж обычно делает лёгкая модель-классификатор, а не строковая эвристика. Но принцип тот же: одна точка входа, разные модели под разную сложность.
Приём 4. Контролируйте длину контекста и выхода
Раз выходные токены кратно дороже входных, а вход вы оплачиваете целиком, контроль обеих частей даёт прямую экономию. Несколько рабочих практик:
Ограничивайте длину ответа через max_tokens. Это самый недооценённый рычаг. Если вам нужен короткий ответ — классификация, JSON с парой полей, краткое резюме — явно ограничьте максимум выходных токенов. Модель не будет «растекаться», и вы не заплатите за лишнюю генерацию по самой дорогой ставке. Просьба в промпте «отвечай кратко» помогает, но жёсткий лимит max_tokens надёжнее.
Отправляйте только релевантный контекст, а не всё подряд. Соблазн загрузить в запрос всю кодовую базу или весь документ понятен, но за каждый входной токен вы платите. Грамотный отбор (retrieval) — взять только те фрагменты, которые относятся к вопросу, — режет входные расходы напрямую. Вместо договора на 400 страниц — нужный раздел; вместо всего репозитория — релевантные файлы.
Подрезайте историю диалога. В длинных чатах вся история отправляется заново на каждом шаге, и счёт за вход растёт квадратично. Держите окно последних N сообщений или периодически сворачивайте старую часть диалога в краткое резюме вместо того, чтобы тащить её целиком.
Следите за порогами тарификации на длинном входе. У GPT-5.5 и GPT-5.4, согласно прайс-документации OpenAI, при входном контексте свыше 272 000 токенов тарификация всей сессии переключается на повышенную: 2× за вход и 1.5× за выход. Это не доплата за токены сверх порога — это смена ставки для всего запроса целиком. Производные повышенные ставки для GPT-5.5: примерно 700 ₽/1M на вход ($10) и 3225 ₽/1M на выход ($45). Вывод: либо удерживайте вход под 272K грамотным отбором контекста, либо заранее закладывайте удвоенную ставку в бюджет. Подробный разбор этого порога — в статье про GPT-5.5 API за рубли.
Выбирайте модель с адекватным контекстом. Если задача укладывается в 200K токенов, нет смысла платить за модель только ради окна в 1M — но и наоборот: упираться в лимит контекста дешёвой модели на длинных документах тоже не стоит. Контекст моделей виден в каталоге.
Приём 5. Батчинг: асинхронная обработка со скидкой
Если у вас есть большой объём запросов, которые не требуют ответа немедленно — ночная разметка датасета, массовая генерация описаний товаров, прогон тысяч тест-кейсов, пакетная классификация, — их выгодно обрабатывать не по одному в реальном времени, а пачкой через batch-режим.
Batch API Anthropic, по официальной документации, снижает стоимость на 50% по сравнению с обычными запросами; большинство пачек обрабатываются менее чем за час, с гарантией завершения в пределах 24 часов. То есть за отказ от мгновенного ответа вы получаете половинную цену — на больших офлайн-объёмах это прямое двукратное снижение расходов.
Когда батчинг уместен:
- Уместен: офлайн-генерация контента, разметка и обогащение данных, массовая суммаризация, большие прогоны оценки качества (evals), пакетная обработка очередей — всё, где задержка в минуты-часы не критична.
- Не уместен: интерактивные сценарии, где пользователь ждёт ответа здесь и сейчас (чат, автодополнение кода, голосовой ассистент). Здесь нужна низкая задержка, а не пакетная скидка.
Батчинг комбинируется с предыдущими приёмами: можно отправлять офлайн-пачку на бюджетную модель (приём 1) и дополнительно получать batch-скидку — экономия складывается.
Сводный расчёт: сколько экономят приёмы вместе
Приёмы не взаимоисключающие — они складываются. Покажем на одном профиле, как меняется счёт, когда мы применяем их последовательно. Возьмём продукт со 100 000 запросов в месяц, в среднем 2K вход + 1K выход на запрос (200M вход + 100M выход в месяц), у которого 30% входного контекста — повторяющийся системный промпт и справочник.
| Шаг оптимизации | Что делаем | Стоимость/мес (порядок) |
|---|---|---|
| Базовый сценарий | Всё на GPT-5.5, без оптимизаций | ≈ 285 000 ₽ |
| + Маршрутизация 80/20 | 80% потока на DeepSeek, 20% на GPT-5.5 | ≈ 63 000 ₽ |
| + Контроль выхода | Подрезали лишнюю генерацию на ~20% | ≈ 56 000 ₽ |
| + Prompt caching | −90% на повторяющиеся 30% входа (флагман-доля) | ≈ 53 000 ₽ |
Базовый счёт: 200M × 350 ₽/1M (вход) + 100M × 2150 ₽/1M (выход) = 70 000 + 215 000 = 285 000 ₽. После маршрутизации основной поток уходит на дешёвую модель, и именно этот шаг даёт главный скачок экономии — со 285 000 до ≈ 63 000 ₽. Дальнейшие приёмы дошлифовывают результат.
Цифры приблизительные и зависят от вашего реального распределения запросов и доли повторяющегося контекста — это иллюстрация порядка эффекта, а не точный прайс. Но направление однозначно: основную экономию даёт маршрутизация и выбор модели, кэширование и контроль выхода добавляют сверху. И поскольку у Promptra нет наценки на токены, весь этот выигрыш остаётся у вас, а не теряется на надбавке посредника.
Почему у Promptra экономия достаётся вам без наценки
Все приёмы выше работают с любым доступом к LLM. Но величина итоговой экономии зависит от того, по какой ставке вы платите за базовый токен. Многие российские агрегаторы добавляют собственную наценку поверх прайса провайдера — и тогда часть вашей оптимизации уходит на эту надбавку.
У Promptra модель другая:
- Цена токенов — 1-в-1 с провайдером по курсу ЦБ РФ. Наценки на токены нет (
ourMarkup = 0в каталоге). Стоимость GPT-5.5, Opus 4.7, DeepSeek и остальных моделей равна официальному прайсу провайдера, пересчитанному по курсу ЦБ. Любая экономия от оптимизации достаётся вам полностью. - Сервисная комиссия 5% — только при пополнении баланса. Она берётся за работу сервиса (эквайринг, биллинг, поддержку), один раз при пополнении, а не с каждого запроса. На стоимость токенов и на эффект от ваших оптимизаций она не влияет.
- Все модели через один endpoint. Маршрутизация и переключение моделей не требуют отдельной интеграции под каждого провайдера — меняется только поле
model,base_urlодин.
Для команд в компаниях важно ещё и то, как эти расходы проходят по бухгалтерии. Promptra принимает оплату на российское юр.лицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — с полным пакетом закрывающих документов: договор-оферта, счёт, акт, счёт-фактура, УПД. Документооборот идёт через ЭДО (Диадок, СБИС). Это значит, что расходы на API корректно ложатся в учёт компании — а без правильно оформленной первички затраты на нейросети к учёту бизнеса не принимаются. Юридическую сторону вопроса (можно ли вообще использовать зарубежные LLM на юрлицо в РФ) мы разобрали отдельно в материале легально ли использовать OpenAI и Claude на юрлицо.
Подключение — drop-in: в коде на OpenAI SDK меняется один параметр base_url на https://api.promptra.ru/v1, дальше работают и выбор модели, и кэширование, и батчинг — ровно как у провайдера. Обзор доступа к моделям OpenAI из России есть на странице ChatGPT API.
FAQ
Как снизить расходы на LLM API быстрее всего?
Самый быстрый и сильный рычаг — выбор модели под задачу и маршрутизация. Перенос массовых простых запросов (классификация, извлечение, короткие ответы) с флагмана на бюджетную модель вроде DeepSeek V4 Pro срезает стоимость выхода в десятки раз: 60 ₽ за 1M против 2150 ₽ у GPT-5.5. Флагман при этом оставляют только для действительно сложных запросов. Это даёт основную экономию ещё до кэширования и батчинга.
Сколько стоит нейросеть по API в рублях?
Зависит от модели и объёма. В каталоге Promptra ставки за 1M токенов идут от 10/20 ₽ (вход/выход) у бюджетных моделей вроде MiMo V2 Pro до 350/2150 ₽ у флагмана GPT-5.5 — это цена 1-в-1 с прайсом провайдера по курсу ЦБ РФ, без наценки. Итоговая стоимость месяца считается так: входные токены за месяц / 1M × ставку входа + выходные / 1M × ставку выхода. Поскольку выход обычно в 5–6 раз дороже входа, основной счёт формирует именно генерация.
Что такое prompt caching и сколько он экономит?
Это кэширование повторяющегося контекста (системный промпт, справочник, примеры). При повторных запросах уже обработанный префикс оплачивается со скидкой: у OpenAI и Anthropic кэшированное чтение стоит около 10% от обычной входной ставки (−90%), у DeepSeek кэширование на диске включено по умолчанию без изменений в коде. Эффект максимален, когда большой неизменный блок переиспользуется во многих запросах — например, в чат-ботах и RAG-пайплайнах.
Дешёвая модель сильно проигрывает флагману по качеству?
На простых задачах — почти нет. Классификация, извлечение полей, модерация, короткие ответы одинаково хорошо решаются и бюджетной моделью, и флагманом, а в цене разница до 35 раз. Флагман реально нужен там, где требуется глубокое многошаговое рассуждение и цена ошибки высока: сложный код, агентные пайплайны, длинный анализ. Оптимальная стратегия — маршрутизация: дешёвая модель на потоке, флагман на сложных запросах.
Помогает ли батчинг экономить и когда его применять?
Да. Batch-режим (например, Message Batches API у Anthropic) даёт скидку 50% за то, что вы не требуете ответа мгновенно — пачка обрабатывается асинхронно, обычно менее чем за час, с гарантией в пределах 24 часов. Применяйте его для офлайн-задач: разметка данных, массовая генерация, прогоны evals, пакетная обработка очередей. Для интерактивных сценариев (чат, автодополнение) батчинг не подходит — там нужна низкая задержка.
Влияет ли наценка агрегатора на экономию от оптимизации?
Да, напрямую. Если агрегатор добавляет наценку на токены, часть вашей экономии от выбора модели, кэширования и батчинга уходит на эту надбавку. У Promptra наценки на токены нет — цена 1-в-1 с провайдером по курсу ЦБ, поэтому весь выигрыш от оптимизации остаётся у вас. Сервисная комиссия 5% берётся только при пополнении баланса и на стоимость токенов не влияет.
Если хотите посчитать экономию под вашу реальную нагрузку — прикинуть, сколько даст маршрутизация и кэширование именно на вашем профиле запросов, и какую связку моделей выбрать — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Поможем собрать схему «дешёвая модель на потоке, флагман по необходимости» и оценить бюджет с закрывающими документами.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.