Эмбеддинг — это представление текста в виде вектора чисел, где близкие по смыслу тексты оказываются рядом в пространстве. На эмбеддингах строят семантический поиск, RAG (ответы по своей базе знаний), классификацию и поиск дубликатов. Для большинства задач разумный дефолт — text-embedding-3-small (дёшево, 1536 измерений), а где важна точность — text-embedding-3-large (3072 измерения). Обе модели вызываются через один OpenAI-совместимый эндпоинт из России без VPN: в коде на openai SDK меняется только base_url на https://api.promptra.ru/v1, оплата идёт в рублях на юр.лицо с закрывающими документами.
Ниже — разбор простыми словами, что такое эмбеддинги и где они применяются, какие модели и размерности бывают, как получить вектор по API (Python и curl), как собрать RAG-пайплайн по шагам (чанк → эмбеддинг → векторная БД → поиск → ответ), сколько это стоит в рублях и какие ошибки встречаются чаще всего. Тон — для разработчика, который хочет понять механику и цену, а не читать маркетинг.
Что такое эмбеддинги простыми словами
Компьютер не понимает текст так, как человек. Чтобы машина могла сравнивать фразы по смыслу, текст нужно перевести в числа. Эмбеддинг — это и есть такой перевод: модель-эмбеддер берёт строку («как сбросить пароль») и возвращает список из сотен или тысяч чисел — вектор. Вектор фиксированной длины, не зависящей от длины текста: и одно слово, и целый абзац превращаются в вектор одной и той же размерности.
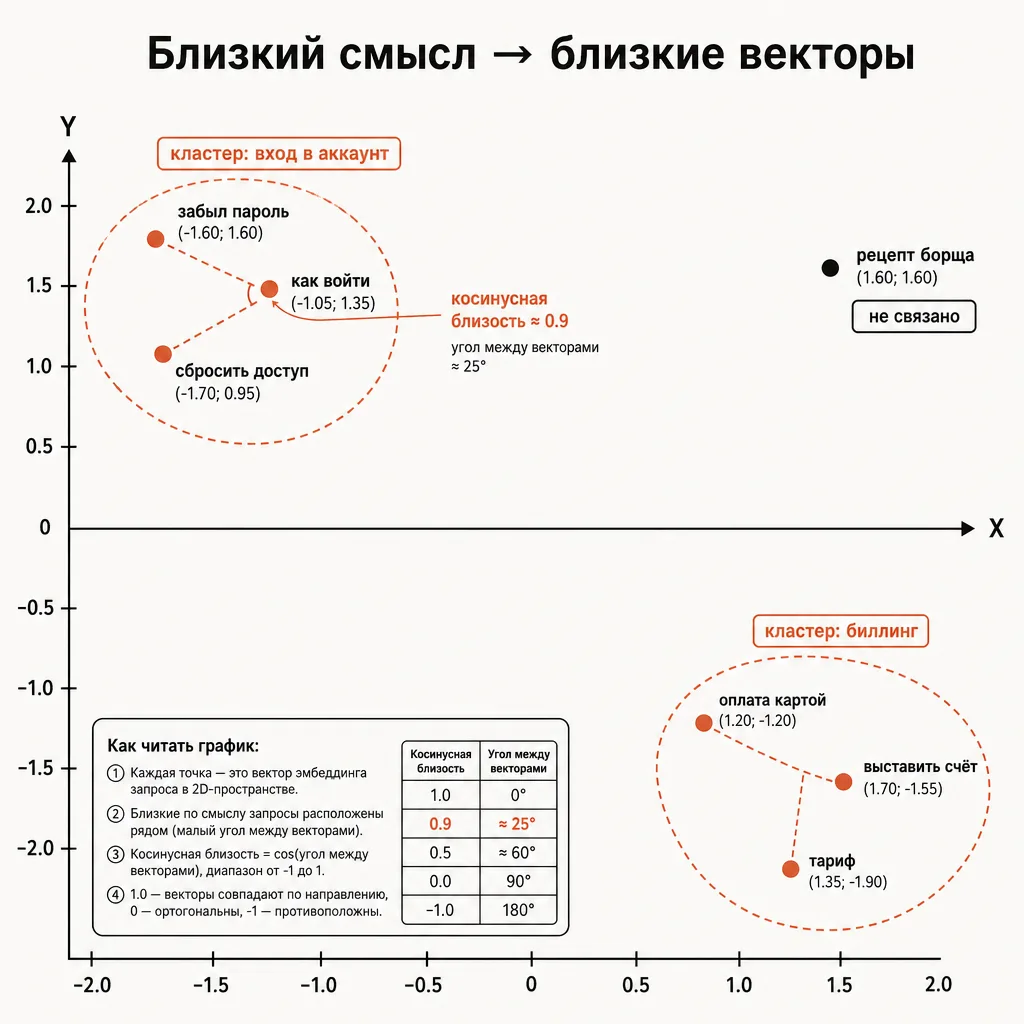
Главное свойство этих векторов: близость в пространстве отражает близость по смыслу. Фразы «как сбросить пароль» и «забыл пароль, что делать» дадут векторы, расположенные рядом, хотя в них почти нет общих слов. А «как сбросить пароль» и «рецепт борща» окажутся далеко друг от друга. Это принципиально отличается от обычного текстового поиска по ключевым словам: там совпадение ищется по буквам, а в семантическом поиске — по смыслу.
Расстояние между векторами измеряют чаще всего косинусной близостью (cosine similarity) — насколько совпадает «направление» двух векторов. Значение около 1 — тексты почти про одно и то же, около 0 — никак не связаны. Именно эта метрика лежит в основе семантического поиска: чтобы найти релевантные документы, мы считаем близость вектора запроса к векторам всех документов и берём самые близкие.
Где применяются эмбеддинги
Эмбеддинги — это инфраструктурный кирпич, на котором держится сразу несколько практических задач:
- Семантический поиск. Поиск по смыслу, а не по словам. Пользователь спрашивает «не приходит письмо подтверждения» — система находит статью «проблемы с доставкой email», даже если в ней нет слова «подтверждение».
- RAG (Retrieval-Augmented Generation). Самое популярное применение. Перед тем как задать вопрос языковой модели, мы находим в своей базе знаний релевантные фрагменты (через эмбеддинги) и подкладываем их в промпт. Модель отвечает не из «головы», а по вашим документам — точнее и без выдумок.
- Классификация и маршрутизация. Тикеты, обращения, лиды можно раскладывать по категориям, сравнивая их эмбеддинги с эталонными. Без обучения отдельной модели.
- Кластеризация и дедупликация. Сгруппировать похожие отзывы, найти дубли товаров в каталоге, выделить темы в массиве сообщений.
- Рекомендации. «Похожие товары», «похожие статьи» — это поиск ближайших векторов к текущему объекту.
Объединяет все эти задачи одно: вместо того чтобы сравнивать тексты по словам, мы сравниваем их по смыслу — а для этого сначала превращаем каждый текст в вектор.
Модели эмбеддингов и размерности
Самые распространённые модели эмбеддингов — линейка OpenAI text-embedding-3. Они доступны через OpenAI-совместимый API, и именно их чаще всего подключают в РФ-проектах. Ключевые параметры:
| Модель | Размерность по умолчанию | Сильная сторона | Цена OpenAI (USD / 1M токенов) |
|---|---|---|---|
text-embedding-3-small | 1536 | Дёшево, быстро, дефолт | $0.02 |
text-embedding-3-large | 3072 | Максимальное качество | $0.13 |
text-embedding-ada-002 (legacy) | 1536 | Старая, для совместимости | $0.10 |
USD-прайс — с официальной страницы OpenAI. Рублёвые оценки разберём в разделе про цену ниже.
Что значит размерность. Это длина вектора — сколько чисел в нём. У text-embedding-3-small по умолчанию 1536 чисел, у large — 3072. Чем больше размерность, тем больше «нюансов» смысла модель может закодировать, но тем больше места занимает вектор в базе и тем дороже его хранить и сравнивать. Для большинства задач 1536 измерений small — более чем достаточно.
Параметр dimensions — важная фишка. Модели text-embedding-3 (в отличие от старой ada-002) умеют отдавать укороченный вектор без потери большей части качества. Передаёте dimensions=512 — и получаете вектор из 512 чисел вместо 1536. Это экономит память векторной базы и ускоряет поиск, а просадка в качестве на типичных задачах небольшая. Приём называется Matryoshka-представление: вектор «вложен» так, что первые N чисел уже несут основной смысл. На практике для экономии берут 512 или 256 измерений у large и часто получают качество не хуже полного small.
Какую модель выбрать по умолчанию:
- Начинайте с
text-embedding-3-small. Дёшево, быстро, на 90% задач (поиск по базе знаний, классификация тикетов, рекомендации) её хватает с запасом. - Берите
text-embedding-3-large, когда важна точность ранжирования: юридический или медицинский поиск, многоязычный корпус, тонкие смысловые различия. При желании укоротите вектор черезdimensions, чтобы не раздувать базу. ada-002— только для совместимости со старым кодом. Для новых проектов смысла нет:3-smallдешевле в пять раз и качественнее.

Как получить эмбеддинг по API
Хорошая новость: эмбеддинги вызываются тем же openai SDK, что и чат — отличается только метод (embeddings.create вместо chat.completions.create). А чтобы работать из России без VPN, меняется ровно один параметр — base_url. Остальной код остаётся как в любом примере из документации OpenAI.
Python
Минимальный рабочий пример — получить вектор для одной строки:
from openai import OpenAI
client = OpenAI(
api_key="prm-xxxxxxxxxxxxxxxx",
base_url="https://api.promptra.ru/v1", # единственное изменение
)
resp = client.embeddings.create(
model="text-embedding-3-small",
input="Как сбросить пароль от личного кабинета",
)
vector = resp.data[0].embedding
print(len(vector)) # 1536 — размерность вектора
print(resp.usage.total_tokens) # сколько токенов потраченоВ ответе resp.data — это список (по одному элементу на каждый входной текст), а resp.data[0].embedding — сам вектор: список из 1536 чисел типа float. Поле resp.usage.total_tokens показывает фактический расход, по которому считается оплата.
Батч — несколько текстов за один запрос. Это важный приём для экономии: вместо тысячи отдельных запросов отправляйте список строк, и модель вернёт список векторов в том же порядке. Так индексируют базу знаний:
texts = [
"Как сбросить пароль",
"Не приходит письмо с подтверждением",
"Как изменить тариф",
]
resp = client.embeddings.create(
model="text-embedding-3-small",
input=texts, # список строк — батч
)
for i, item in enumerate(resp.data):
print(i, len(item.embedding)) # вектор для каждого текста по порядкуУкороченный вектор через dimensions — когда нужно сэкономить на хранении и поиске:
resp = client.embeddings.create(
model="text-embedding-3-large",
input="Текст запроса",
dimensions=512, # вместо 3072 по умолчанию
)
print(len(resp.data[0].embedding)) # 512Параметр dimensions поддерживается только у моделей text-embedding-3 и новее — у старой ada-002 его нет.
curl
Проверить эндпоинт без всякого SDK можно одним запросом:
curl https://api.promptra.ru/v1/embeddings \
-H "Authorization: Bearer prm-xxxxxxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "text-embedding-3-small",
"input": "Как сбросить пароль от личного кабинета"
}'Если в ответе пришёл JSON с полем data, внутри которого массив embedding из чисел, — эндпоинт и ключ в порядке, можно индексировать базу. Подробный разбор того, как поменять base_url в разных SDK и на разных языках, — в гайде миграция с OpenAI SDK: меняем base_url.
Как построить RAG и семантический поиск
RAG расшифровывается как Retrieval-Augmented Generation — «генерация с подмешиванием найденного». Идея простая: языковая модель не знает содержимого ваших внутренних документов, и если спросить её напрямую, она либо ответит общими словами, либо выдумает. RAG решает это так: перед ответом мы находим в своей базе релевантные фрагменты (через эмбеддинги) и кладём их прямо в промпт. Модель отвечает уже по конкретным данным.
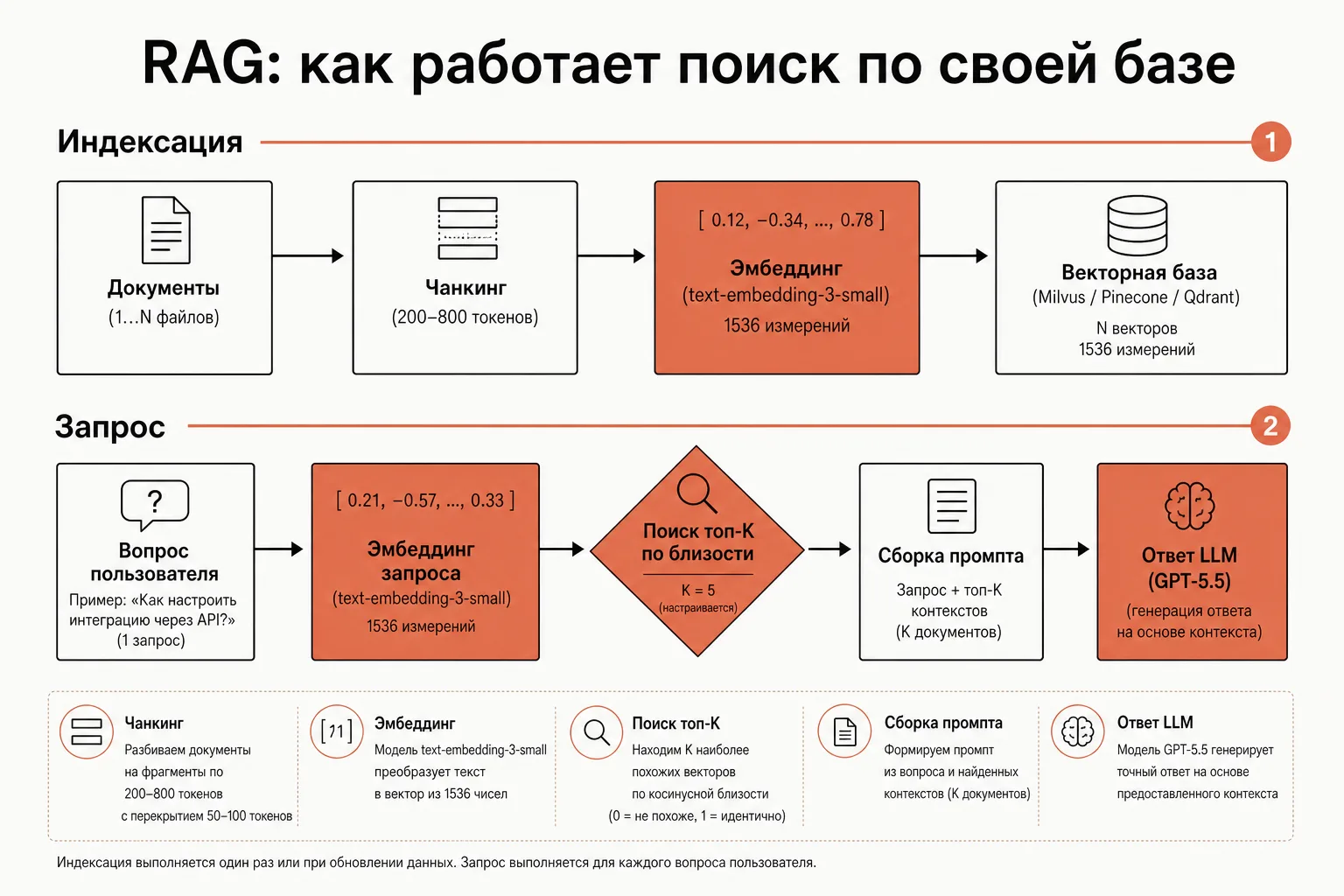
Пайплайн состоит из двух фаз — индексация (один раз, заранее) и запрос (на каждый вопрос пользователя).
Фаза 1. Индексация базы знаний
- Чанкинг. Документы (статьи, инструкции, договоры) режутся на куски — чанки — по 200–800 токенов. Слишком большие чанки размывают смысл, слишком мелкие теряют контекст. Типичный старт — абзацы или фрагменты по 300–500 токенов с небольшим перекрытием.
- Эмбеддинг. Для каждого чанка получаем вектор через
embeddings.create(батчами, как показано выше). - Сохранение в векторную БД. Вектор плюс исходный текст чанка и метаданные (источник, заголовок) складываются в векторную базу.
Фаза 2. Запрос пользователя
- Эмбеддинг запроса. Вопрос пользователя превращаем в вектор той же моделью.
- Поиск ближайших (топ-K). Векторная БД находит K чанков, ближайших к запросу по косинусной близости (обычно K = 3–8).
- Сборка промпта. Найденные чанки вставляем в системный промпт: «Ответь на вопрос, используя только эти фрагменты: …».
- Генерация ответа. Отправляем промпт в чат-модель (например, GPT-5.5 или Claude Sonnet) — она отвечает по подложенным данным.
Ключевой момент: эмбеддер и чат-модель — это разные модели, и они работают вместе. Эмбеддер (text-embedding-3-small) отвечает за поиск, чат-модель (gpt-5.5, claude-sonnet-4-6 и т.д.) — за формулировку ответа. Обе доступны через один и тот же эндпоинт — меняется только значение model.
Минимальный RAG-цикл на Python, без внешней векторной БД (для базы из нескольких сотен чанков хватает поиска в памяти через numpy):
import numpy as np
from openai import OpenAI
client = OpenAI(api_key="prm-xxxx", base_url="https://api.promptra.ru/v1")
# --- Индексация (один раз) ---
chunks = [
"Чтобы сбросить пароль, откройте раздел Настройки и нажмите Сбросить.",
"Письмо с подтверждением приходит в течение 5 минут, проверьте папку Спам.",
"Сменить тариф можно в Биллинге, изменения вступают в силу сразу.",
]
emb = client.embeddings.create(model="text-embedding-3-small", input=chunks)
index = np.array([d.embedding for d in emb.data]) # матрица векторов
# --- Запрос ---
question = "не могу войти, забыл пароль"
q = client.embeddings.create(
model="text-embedding-3-small", input=question
).data[0].embedding
q = np.array(q)
# косинусная близость и топ-K
sims = index @ q / (np.linalg.norm(index, axis=1) * np.linalg.norm(q))
top_k = sims.argsort()[::-1][:2]
context = "\n".join(chunks[i] for i in top_k)
# --- Генерация ответа по найденному контексту ---
answer = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": f"Ответь, используя только эти данные:\n{context}"},
{"role": "user", "content": question},
],
)
print(answer.choices[0].message.content)На больших объёмах (десятки тысяч чанков и больше) поиск в памяти заменяют на специализированную векторную БД — pgvector (расширение PostgreSQL), Qdrant, Chroma, Milvus или подобные. Логика та же: складываете векторы, ищете ближайшие. Меняется только хранилище — эмбеддинги по-прежнему берёте через тот же API.
Цена эмбеддингов в рублях
Здесь важная оговорка: цены на модели эмбеддингов в нашем каталоге отдельной строкой пока не зафиксированы (каталог сейчас отражает чат-модели). Поэтому рублёвые значения ниже — производная оценка: официальная цена OpenAI в долларах, умноженная на курс ЦБ РФ 71.668 ₽/$ (на 2026-05-27, тот же курс, что и для всех моделей в каталоге). Фактический счёт считается по курсу ЦБ на день пополнения и без наценки на токены; точные ставки по эмбеддингам уточняйте у команды при подключении.
| Модель | Цена OpenAI (USD / 1M) | Оценка в ₽ / 1M (× 71.668) |
|---|---|---|
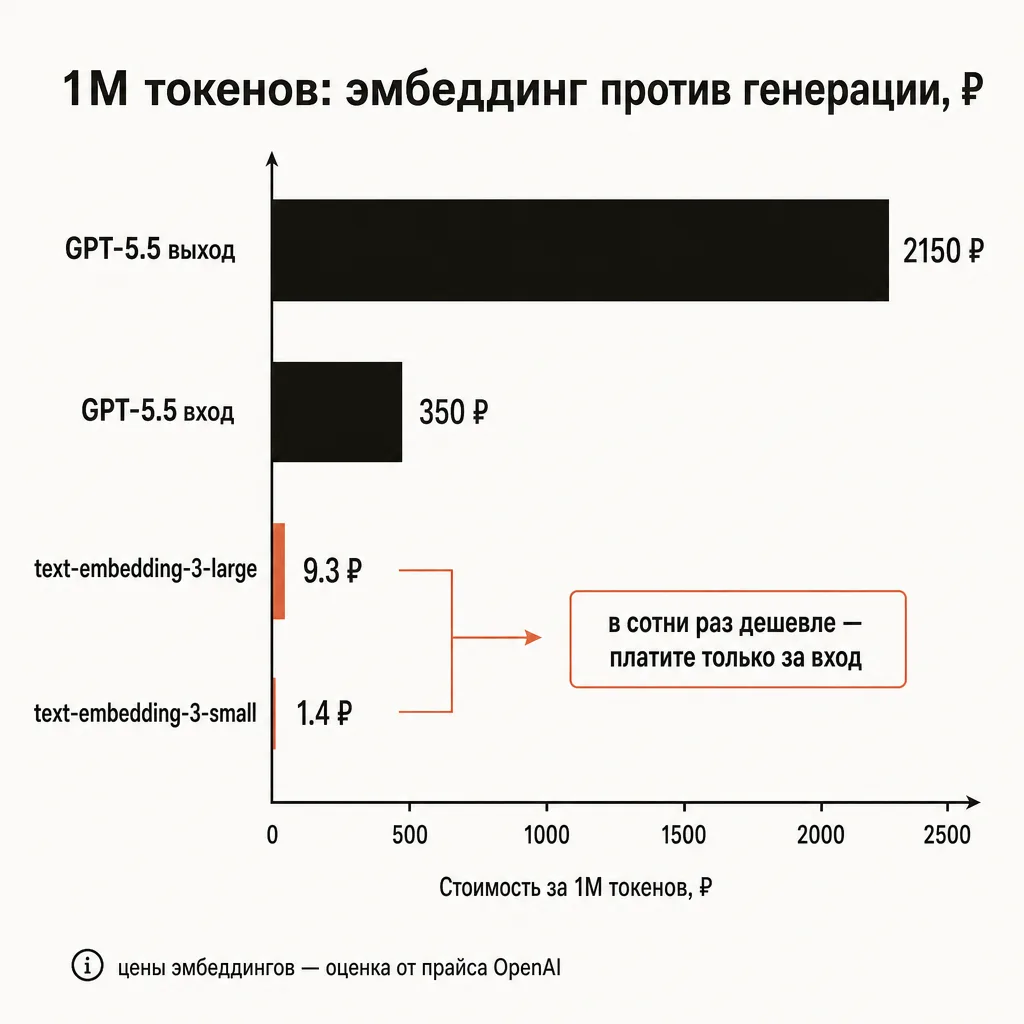
text-embedding-3-small | $0.02 | ≈ 1.4 ₽ |
text-embedding-3-large | $0.13 | ≈ 9.3 ₽ |
text-embedding-ada-002 | $0.10 | ≈ 7.2 ₽ |
Главное, что бросается в глаза: эмбеддинги несопоставимо дешевле генерации. Миллион токенов через text-embedding-3-small обходится примерно в 1.4 ₽ — это в сотни раз дешевле, чем тот же миллион токенов на выходе у чат-флагмана (для сравнения, выход GPT-5.5 — 2150 ₽ за 1M). Причина в том, что эмбеддер только «читает» текст и отдаёт один вектор, он ничего не генерирует. Платите вы только за входные токены — понятия «выходных токенов» у эмбеддингов нет.
Прикинем реальные сценарии (по оценочной ставке text-embedding-3-small ≈ 1.4 ₽ за 1M):
| Сценарий | Объём | Примерно токенов | Стоимость (оценка) |
|---|---|---|---|
| Проиндексировать базу знаний на 1000 статей | ≈ 1000 × 800 токенов | 0.8M | ≈ 1.1 ₽ |
| Проиндексировать 100 000 товаров каталога | ≈ 100K × 100 токенов | 10M | ≈ 14 ₽ |
| 1 млн поисковых запросов в месяц | ≈ 1M × 20 токенов | 20M | ≈ 28 ₽ |
Даже индексация крупной базы и миллион запросов в месяц складываются в десятки рублей. Эмбеддинги — та статья расходов, по которой в RAG-системе экономить обычно не нужно: основной счёт формирует чат-модель, генерирующая ответы, а не эмбеддер. Поэтому выбор large вместо small ради качества почти не бьёт по бюджету.
> Важно: значения в таблицах — производная оценка от долларового прайса OpenAI по курсу ЦБ, а не строка из каталога. Перед расчётом бюджета сверьте актуальную ставку с командой.
Типичные ошибки при работе с эмбеддингами
Несколько граблей, на которые наступают чаще всего:
Разные модели для индексации и запроса. Векторы от text-embedding-3-small и text-embedding-3-large живут в разных пространствах — их нельзя сравнивать между собой. Если вы проиндексировали базу одной моделью, а запросы считаете другой, поиск выдаст мусор. Правило: одна и та же модель (и одна и та же размерность) на индексацию и на запрос. Сменили модель — переиндексируйте всю базу.
Слишком крупные чанки. Если затолкать в один чанк целую страницу, его вектор «усреднит» все темы сразу, и поиск по конкретному вопросу станет размытым. Дробите на смысловые куски по 200–800 токенов. Обратная крайность — чанки по одному предложению — теряют контекст. Истина посередине, обычно абзац.
Игнорирование лимита длины входа. У моделей эмбеддингов есть максимум токенов на один вход (у text-embedding-3 это 8191 токен). Текст длиннее обрежется или вызовет ошибку — длинные документы нужно резать на чанки до эмбеддинга, а не после.
Отказ от батчинга. Индексировать базу по одному тексту на запрос — медленно и упирается в rate limit. Отправляйте списком (батчами по сотне-другой строк) — это и быстрее, и устойчивее к лимитам.
Хранение векторов как есть без нормализации. Многие векторные БД и метрики ожидают нормализованные векторы (длины 1). Если считаете близость вручную через скалярное произведение — либо нормализуйте, либо используйте честную косинусную формулу с делением на нормы (как в примере выше).
Эмбеддинг очень разноязычного корпуса дешёвой моделью. На многоязычных и узкоспециальных данных text-embedding-3-small иногда заметно уступает large. Если поиск «промахивается» на вашем корпусе — первое, что стоит попробовать, это поднять модель до large, благо по цене это почти незаметно.
Если по тексту нужно не только искать, но и генерировать (ответы, резюме, код) — выбор чат-модели под задачу и бюджет мы разобрали в гайде нейросеть для кода: какие LLM выбрать, а обзор топовых моделей — в материале топ-5 LLM 2026. Подключить чат-модели можно на странице ChatGPT API — тем же ключом и эндпоинтом, что и эмбеддинги.
Оплата и документы для юр.лица
Для компаний важна не только техническая сторона, но и то, как расходы на API проходят по бухгалтерии. Оплата идёт на юр.лицо — ООО «ТРАФИК АГРЕГАТОР» (ИНН 9707022118) — с полным пакетом закрывающих документов через ЭДО: договор-оферта, счёт, акт, счёт-фактура, УПД. Документы автоматически проводятся в учётной системе через операторов ЭДО (Диадок, СБИС).
Цена за токены — 1-в-1 с прайсом провайдера, пересчитанным по курсу ЦБ, без наценки на сами токены; сервисная комиссия 5% берётся только при пополнении баланса. Доступ работает из России без VPN: запрос уходит на эндпоинт агрегатора, а он связывается с провайдером со своей стороны — туннелировать трафик или маскировать IP не нужно.
FAQ
Что такое эмбеддинги простыми словами?
Эмбеддинг — это перевод текста в вектор чисел, в котором близкие по смыслу тексты оказываются рядом. Модель-эмбеддер берёт строку и возвращает список из сотен или тысяч чисел фиксированной длины. Благодаря этому компьютер может сравнивать тексты по смыслу, а не по буквам: фразы «забыл пароль» и «как восстановить доступ» дадут близкие векторы, хотя общих слов в них почти нет. На этом свойстве строят семантический поиск, RAG, классификацию и рекомендации.
Какую модель эмбеддингов выбрать?
По умолчанию — text-embedding-3-small: дёшево, быстро, размерность 1536, на большинстве задач (поиск по базе знаний, классификация, рекомендации) её хватает с запасом. Если важна максимальная точность — text-embedding-3-large (3072 измерения), особенно на многоязычных и узкоспециальных корпусах. Старую ada-002 для новых проектов брать смысла нет — 3-small дешевле в пять раз и качественнее. У моделей text-embedding-3 можно укоротить вектор параметром dimensions, чтобы сэкономить на хранении.
Сколько стоят эмбеддинги в рублях?
Эмбеддинги несопоставимо дешевле генерации, потому что вы платите только за входные токены — выходных у них нет. Оценочно (производная от прайса OpenAI по курсу ЦБ 71.668 ₽/$): text-embedding-3-small ≈ 1.4 ₽ за 1M токенов, text-embedding-3-large ≈ 9.3 ₽ за 1M. Проиндексировать базу из тысячи статей стоит порядка рубля, миллион поисковых запросов в месяц — десятки рублей. Это оценка от долларового прайса, а не строка каталога; точную ставку уточняйте у команды при подключении.
Что такое RAG и при чём тут эмбеддинги?
RAG (Retrieval-Augmented Generation) — это подход, когда перед ответом языковая модель получает в промпт релевантные фрагменты из вашей базы знаний, а не отвечает «из головы». Эмбеддинги обеспечивают первый шаг — поиск этих фрагментов: документы заранее режутся на чанки и превращаются в векторы, а вопрос пользователя сравнивается с ними по смыслу. Найденные топ-K чанков подкладываются в промпт чат-модели. Эмбеддер ищет, чат-модель формулирует ответ — и обе вызываются через один API.
Можно ли использовать эмбеддинги из России без VPN?
Да. Эмбеддинги вызываются через OpenAI-совместимый эндпоинт: в коде меняется один параметр base_url на https://api.promptra.ru/v1, а запросы проксируются легально со стороны агрегатора. Маскировать IP или поднимать VPN не нужно. Оплата идёт в рублях на юр.лицо с закрывающими документами, что удобнее и стабильнее связки «VPN плюс зарубежная карта», которая регулярно отваливается.
Нужна ли отдельная векторная база данных для RAG?
Не всегда. Для небольшой базы (до нескольких сотен или тысяч чанков) хватает поиска ближайших векторов прямо в памяти, например через numpy — это десяток строк кода. Специализированная векторная БД (pgvector, Qdrant, Chroma, Milvus) нужна на больших объёмах — десятки тысяч векторов и больше, когда важны скорость поиска и фильтрация по метаданным. Логика при этом не меняется: эмбеддинги вы по-прежнему получаете через тот же API, меняется только хранилище.
Если вы хотите подобрать модель эмбеддингов под свой корпус, прикинуть стоимость индексации базы или обсудить подключение RAG-пайплайна с закрывающими документами — напишите команде Promptra напрямую в Telegram: t.me/nesterov_av. Не маркетингу и не саппорту первой линии, а живому человеку: вопрос с выбором моделей и расчётом бюджета обычно решается за один разговор.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.
Promptra
Готовы попробовать Promptra?
Один API-ключ ко всем флагманским LLM. Оплата на юр.лицо, цены в рублях по курсу ЦБ. Тестовые токены бесплатно.